- Asinerum Project Commander said... (4602)


- Ref: Asinerum Project Commander (4601)
5. Nhiệmvụ của chúng Bò là tínhtoán {thetaZero} mý {thetaOne}, dúng chưa?
Vậy thì, như Zì giảng above, chúng cô cứ dặt mẹ 2 con dó bằng zero:
let thetaOne = 0;
let thetaZero = 0;
Zĩnhiên chúng sẽ khác xa kếtquả cuốicùng, nhưng kệ con mẹ chúng di. -
 Wed May 13, 04:18:00 PM 2020
Wed May 13, 04:18:00 PM 2020
- Asinerum Project Commander said... (4603)
- Ref: Asinerum Project Commander (4602)
6. Ngoài việc giảdịnh Chiếnthuật Leo Núi dơnsơ nhất, aka cho {thetaZero} mý {thetaOne} bằng mẹ 0, thì cáy dcm, như con Cơ giảng phía xa trên, chúng cô cũng cần giảdịnh [tươngdối] nghiêmtúc dộ-zài của mỗi bước-chân, mà hànlâm kêu là LEARNING RATE.
Chiếnthuật Leo Núi tượngtrưng cho hướng chúng cô sẽ leo, còn Dộ-zài Bước-chân (aka Learning Rate) sẽ tượngtrưng cho tốcdộ leo.
Nếu Bước của chúng cô quá Zài, thì cothe chúng cô sẽ leo mẹ lên một chỏm núi khác, chứ déo leo dúng hướng mụctiêu.
Ngược lại, nếu Bước của chúng cô quá Ngắn, thì chúng cô sẽ tốn thờigian.
Việc xácdịnh Dộ-zài Bước-chân dó, chúng Bò sẽ mần theo kinhnghiệm thoy.
Vì sao hànlâm kêu Dộ-zài Bước-chân là Learning Rate? Dơngiản vì chúng muốn kháiquát hànhvi Zạy Máy, chứ không chỉ loanhquanh nhõn trò Leo Núi. Chúng cô bước 1 bước, cũng như máytính học 1 bài. - Wed May 13, 04:35:00 PM 2020
- Asinerum Project Commander said... (4604)
- Ref: Asinerum Project Commander (4603)
7. Và tại một bàitoán cụtỷ, mý {x} và {y} bằng:
x = [40, 77, 110];
y = [78, 130, 190];
Hehe thì, cứ dặt mẹ bước-chân zài 0.0003 câylômét. Nhớ rằng, dây là chảzụ thoy, dừng thắcmắc sao bước-chân déo gì lạlùng vậy. Nếu nom nó nhỏ hay nhớn quá, thì cứ thay mẹ dơnvị dolường, là xong. Nghĩa là:
const LEARNING_RATE = 0.0003; - Wed May 13, 04:42:00 PM 2020
- Asinerum Project Commander said... (4605)
- Ref: Asinerum Project Commander (4604)
8. Như Zì giảng above, thì nguyênlý của môn Zạy Máy Leo Núi, sẽ là, cứ sau 1 bước-chân (aka 1 cú Luyện Máy), thì các con {thetaZero} mý {thetaOne} phải dược diềuchỉnh lại, dặng hướng-bước tiếptheo dảmbảo dúng hướng dạohàm. - Wed May 13, 05:03:00 PM 2020
- Asinerum Project Commander said... (4606)

- Ref: Asinerum Project Commander (4605)
9. Nếu dặt dộ-zài bước-chân là {alpha}, mà phía-trên Zì kêu là Learning Rate, còn số bước Leo Núi zựkiến là {M} (trong vízụ cụtỷ thì M=3, là kíchthước của mảng zữliệu dầuvào {x} hay {y} dódó), thì hàm Zạy Máy Leo Núi sẽ như sau:
const learn = function(alpha) {
let thetaZeroSum = 0;
let thetaOneSum = 0;
for (let i = 0; i < M; i++) {
thetaZeroSum += hypothesis(x[i]) - y[i];
thetaOneSum += (hypothesis(x[i]) - y[i]) * x[i];
}
thetaZero = thetaZero - (alpha / M) * thetaZeroSum;
thetaOne = thetaOne - (alpha / M) * thetaOneSum;
}
Chúng Bò nom chưa? Hai anh {thetaOne} và {thetaZero} sẽ dược diềuchỉnh sau mỗn bước-chân.
Dcm số bước-chân trong vízụ Zì nêu nhõn bằng 3, chứ thựctế thì nó càng nhớn càng ngoan, nghĩa là các anh thetaOne và thetaZero sẽ càng chínhxác. - Wed May 13, 05:20:00 PM 2020
- Asinerum Project Commander said... (4607)
- Ref: Asinerum Project Commander (4606)
10. Và toànbộ code cho bàitoán hồiquy tuyếntính mý zữliệu dầuvào bebé sẽ như sau:
// Nhập zữliệu dầuvào:
let x = [40, 77, 110];
let y = [78, 130, 190];
let M = x.length;
// Giảdịnh dộ-zài bước-chân:
const LEARNING_RATE = 0.0003;
// Khởitạo chiếnlược leo-núi:
let thetaOne = 0;
let thetaZero = 0;
let hypothesis = function(x) {
return (thetaZero + thetaOne * x);
}
// Biên hàm Leo Núi:
const learn = function(alpha) {
let thetaZeroSum = 0;
let thetaOneSum = 0;
for (let i = 0; i < M; i++) {
thetaZeroSum += hypothesis(x[i]) - y[i];
thetaOneSum += (hypothesis(x[i]) - y[i]) * x[i];
}
thetaZero = thetaZero - (alpha / M) * thetaZeroSum;
thetaOne = thetaOne - (alpha / M) * thetaOneSum;
} - Wed May 13, 05:31:00 PM 2020
- Asinerum Project Commander said... (4608)
- Ref: Asinerum Project Commander (4607)
11. Cốpbết toànbộ code trên vào NodeJS console, gòy chạy hàm Học Máy:
learn (LEARNING_RATE);
Sau dó, thì in các anh thetaOne và thetaZero ra mà nom:
> thetaOne
3.4029999999999996
> thetaZero
0.039799999999999995
Nghĩa là, hàm hồiquy tuyếntính cho 2 mảng sốmá {x} và {y} above sẽ dược xácdịnh bằng:
y = 3.4*x + 0.04
Giờ thì zùng hàm {y} dó mà thử mý any giátrị {x} chúng cô thích. - Wed May 13, 05:40:00 PM 2020
- Asinerum Project Commander said... (4609)
- Ref: Asinerum Project Commander (4608)
12. Giờ chúng Bò zựdoán giá Phò 2030 như Zì dưa trang trước.
// Nhập sốmá dầuvào:
x = [199912, 200114, 200309, 200810];
y = [50000, 70000, 100000, 120000];
M = x.length;
thetaOne = 0;
thetaZero = 0;
// Chọn Learning Rate bằng 0.0001
// và chạy hàm Zạy Máy Leo Núi:
learn(0.0001);
// In kếtquả hồiquy tuyếntính:
console.log(thetaOne);
> 1703292
console.log(thetaZero);
> 8.5
// Zựdoán giá phò 2030:
gia_pho_2030 = thetaOne*203001 + thetaZero;
Và chúng cô sẽ có kếtquả zựdoán choáng mẹ luôn:
gia_pho_2030 == 350 bịch ôngcụ; - Wed May 13, 06:12:00 PM 2020
- Asinerum Project Commander said... (4610)
- Ref: Asinerum Project Commander (4609)
13. Nếu nghĩ giá Phò dó quá cao, thì chúng cô cothe hạ Learning Rate xuống.
Chúng cô hãy thử xóa mẹ 1 giátrị [cuốicùng] của mảng dầuvào (dang từ 4 xuống còn 3), gòy test các Learning Rate dặng kếtquả zựdoán cho giátrị dó là gần-dúng nhất.
Sau dó, thì cứ Learning Rate dó mà phạng cho các trườnghợp tươnglai.
Cách làm này hànlâm kêu là zựng "test-set" aka zữliệu-thử cho tậphợp sốmá huấnluyện.
Chảzụ bộ số-biên-tay MNIST trứzanh có tổngcộng 70,000 hình dược chọt từ thựctế. Dcm trong dó, hànlâm chọn 60,000 hình làm zữliệu-huấnluyện aka training-set, cònlại 10,000 hình là zữliệu-thử aka test-set.
Các môhình zựdoán sẽ zạy máytính Leo Núi trên 60,000 hình zữliệu-huấnluyện, gòy test mý 10,000 hình zữliệu-thử. Nếu kếtquả test chínhxác trên 98% là môhình ngoan, cothe mang vào thựctế. - Wed May 13, 06:32:00 PM 2020
- Hoàng Cương said... (4611)


- Con Cò hỏi thật đó, rất cầu thị, chứ đéo phải khoe đâu.
Ý định của cỏn là cổ phần nội bộ. Đó là dành cho bọn đệ thân thiết, only. Anh biết.
- Wed May 13, 09:12:00 PM 2020
- Hoàng Cương said... (4612)
- Cổ đông không được bán cổ phần cho bên ngoài. Nếu nghỉ chơi thì buộc phải bán nội bộ, hoặc bán lại cho chính con Cò.
- Wed May 13, 09:14:00 PM 2020
- Hoàng Cương said... (4613)
- Mục đích cổ phần là: Chia bớt trách nhiệm/ phát huy tinh thần mần việc của lũ cò con con con Cò/ để chúng quản lý lẫn nhau nhằm chống thất thoát/ cỏn bớt được thời gian mần việc công ty, dành thời gian cho việc khác/ kiếm thêm được mớ xèng kha khá do tụi cò con dâng nạp.
- Wed May 13, 09:19:00 PM 2020
- Hoàng Cương said... (4614)
- Quá tốt, có phỏng.
Vấn đề là phải thuyết phục bọn cò con chung xèng.
Vậy thì : chúng phải thấy giá đó hời, phải thấy thu nhập tăng lên là một thực tế chứ đéo phải bánh vẽ. Quan trọng nhất, là chúng phải tin con Cò sẽ trung thành luật chơi. - Wed May 13, 09:24:00 PM 2020
- Hoàng Cương said... (4615)
- Vậy thì thỏa thuận và niềm tin nội bộ quan trọng nhất. Thẩm định từ bên ngoài thì có cũng được.
Anh tin con Cò sẵn sàng định giá theo cách mà cỏn và ngay cả tụi cò con cũng cảm nhận được là RẺ.
Nhưng bỉm có chịu xuống xèng hay không lại là một chuyện khác. - Wed May 13, 09:29:00 PM 2020
- Asinerum Project Commander said... (4616)
- Dcm con Cương này theo Zì mãi, học cả MBA gòy, mà ngu sao thiêntài vậy ta.
Cách của cô nói, chính là một hìnhthức cùphânhóa dơnsơ, và các cùpheo dược gọi là cùpheo ưudãi aka preferred-stock aka preferred-share.
Các quydịnh zìa quyềnhạn và tráchnhiệm của cùpheo ưudãi (như cáy déo gì mà không dược bán ra ngoài, không dược bán trước baonhiêu mùa, hay dcm thậmchí cấm chuyểnnhượng, dược hưởng cùtức cả khi côngty chưa có lãi, hay không dược hưởng cùtức, hoặc hưởng cùtức cốdịnh như tráyphiếu, etc) dều phải ghi rõ trong diềulệ côngty.
Còn vụ của con Cò, thì con ý Hỏi Khoe 100% chứ déo gì. Bằngchứng là cỏn dã im như thinthít suốt từ bấy.
- Wed May 13, 10:43:00 PM 2020
- Danko said... (4617)


- Ref: Asinerum Project Commander (4616)
Chị đương bận tý, mai chị gặp shark rồi. Có gì chị báo sau, cáy đcm! Chúng cô mần chủ lò mổ, cũng nghĩ tới việc chia bánh cho bộ đội là vừa. Thí mới văn minh.
Khoe cáy buồi, chị mần thật - Wed May 13, 10:51:00 PM 2020
- Asinerum Project Commander said... (4618)
- Ref: Danko (4617)
Hehe chúng Bò tính bịp ai chứ bịp Zì thế déo nào dược.
Dã "mai gặp shark" thì déo có chuyện "nay chia cho bồdội", và ngược lại. Diều này chắcchắn 100% luôn. - Wed May 13, 11:00:00 PM 2020
- Asinerum Project Commander said... (4619)
- Khi chủ một côngty dịnh "bán cho shark", thì việc này phải dược quyhoạch và tiếnhành trong suốt nhiều mùa, mý diều dầutiên phải làm, là minhbạch báocáo tàichính, trong một thờigian dủ zài, trong dó việc thuê kiểmtoán caoboong là chắcchắn must-do.
Dừng có cãi Zì. Vì càng cãi, thì chúng cô lại càng chothấy, chúng cô chỉ có Cứt mang bán thoy, chứ có cùpheo Cáy Ty Lồn.
Và khi dã dịnh "bán cho shark", thì chủ côngty dã chắccú zìa diều dó, và sẽ déo baogiờ con ý có ýdịnh bán ngay nộibộ. Bởi khi bán cho shark, thì diềulệ côngty sẽ phải hoàntoàn thaydổi, và mọi cáchthức vậnhành cũ của côngty khongthe ápzụng dược nữa.
Sau khi dã ngãngũ mý shark, diềulệ dược cậpnhật, thì mý có chuyện tiếptục cùpheohóa theohướng bán cùpheo ưudãi cho nhânzân côngty, zĩnhiên phải có quyếtdịnh của shark, khi dó cũng dã là một chủ côngty. Và cuốicùng, mý dến côngdoạn bán cho dạichúng.
Ba côngdoạn dó khongthe tiếnhành dồngthời, mà phải lần từng nấc. Dơngiản vì chúng dạp mẹ lên nhau.
Dừng có cãi Zì. Vì càng cãi, thì chúng cô lại càng chothấy, chúng cô chỉ có Cứt mang bán thoy, chứ có cùpheo Cáy Ty Lồn. - Wed May 13, 11:15:00 PM 2020
- Thiên cơ said... (4620)

- Các cô nhớ copy lời giảng của Zì lại về nghiền ngẫm, hoặc học thuộc lòng mẹ lại đặng mà đi phỏng vấn. Qua tai mắt của bọn đệ anh tại Giùn, thì linear regression rất được hay hỏi nơi interview.
@Cô Phím: Chịu khó hóng quán bựa đều đã nâng boong ngay. - Thu May 14, 02:56:00 AM 2020
- Thiên cơ said... (4621)
Thuật toán gradient rất đơn giản, chỉ cần tính đạo hàm và thử bừa learning rate là có thể đem đi đấm ngay lập tức. À còn nữa, trong thực hành với các bài toán phức tạp, chúng mình cũng phải thử hú họa các điểm xuất phát ban đầu nữa. ĐCM, điều này đơn giản thôi, nếu điểm xuất phát ban đầu càng xa chân núi, thì đi càng lâu. Chúng mình đéo biết đang đứng ở đâu, nên phải thử bừa nhiều điểm.
Một chú ý nữa, gradient descent mà anh và Zì giảng là gradient descent ngây thơ,nó đéo đảm bảo tìm được đúng chân núi, mà ổng chỉ tìm được các vũng của núi như thế này thôi, và ổng sẽ mắc kẹt mãi ở đó.
(Wrong image embeded)
Như vậy, càng thêm lý do để chúng mình chọn các điểm xuất phát ban đầu khác nhau nhằm so sánh các vũng núi với nhau, để tìm vũng ngoan nhất. Tuy nhiên, lại hay ở chỗ, là với vài cải biến nho nhỏ, chúng mình sẽ giúp thoát khỏi vũng núi. Vì thế trong thực hành đcm gradient descent là vô địch.
Như Zì đã nói, gradient descent nghĩa đen là xuống dốc, nhưng đcm gọi leo núi cũng đéo sai vì nó đều cùng bản chất. Giờ các cô muốn leo nên đỉnh núi aka tìm giá trị lớn nhất thì chỉ cần đi cùng hướng đạo hàm thay vì ngược hướng nó nghe chưa. Từ rày, thuật ngữ gradient descent trong quán bựa sẽ gọi là "leo núi" mà đéo sợ thắc mắc.
- Thu May 14, 03:28:00 AM 2020
- Thiên cơ said... (4622)
- ĐCM, ảnh đéo lên, anh bốt lại ảnh giải thuật leo núi bị kẹt tại các vũng núi.

- Thu May 14, 03:32:00 AM 2020
- Thiên cơ said... (4624)
- Cái quan trọng nhất trong giải thuật leo núi là tính được đạo hàm aka gradient. Chúng mình tính bằng con tensorflow. Các cô tự gúc cách install ổng. Con nào lười thì ráng chịu.
Hàm đầu tiên là: x^2 + y^2 + z^2 tại điểm (1,2,3) có gradient là (2,4,6). Tính như sau:
import tensorflow as tf
x1 = tf.constant(1.0)
x2 = tf.constant(2.0)
x3 = tf.constant(3.0)
with tf.GradientTape() as tape:
tape.watch([x1,x2,x3])
g = x1**2 + x2**2 + x3**2
grads = tape.gradient(g, [[x1,x2,x3]])
grads
Kết quả trả về là:
(2.0, 4.0, 6.0)
Đúng mẹ như lý thuyết, thật thánh quá đi.
Tiếp theo là con: sqrt(x1+x2)*log(x3). Hehe, con này anh phịa đó, đặng cho vui thôi.
x1 = tf.constant(1.0)
x2 = tf.constant(2.0)
x3 = tf.constant(3.0)
with tf.GradientTape() as tape:
tape.watch([x1,x2,x3])
g = tf.math.sqrt(x1+x2)*tf.math.log(x3)
grads = tape.gradient(g, [[x1,x2,x3]])
grads
Kết quả trả về là:
(0.31714207, 0.31714207, 0.57735026)
Con nào rảnh có thể tự tính, đặng so với ông tensorflow.
Túm lại, nhờ ông tensorflow va thuật toán leo núi, chúng mình đã có thể giải bài toán tối ưu tổn thất. Anh bương nào nghĩ ra giải thuật này quả là thiên tài quá đi. - Thu May 14, 03:46:00 AM 2020
- Asinerum Project Commander said... (4625)
- Ref: Thiên cơ (4624)
Con Tensorflow sửzụng môhình mạng thầnkinh, nên kếtquả của nó ngoan phết dó.
Con nào dịnh chơi Python trên Windows, thì việc nạp Tensorflow sẽ khá khónhọc. Zì phải dánh Python 3.6 chứ nâng lên 3.7 là gặp trụctrặc ngay.
Giảipháp là chạy mẹ một máy-ảo Ubuntu, hoặc múp qua zùng NodeJS.
Ngoài Tensorflow của thằng Gúc, thì còn hàngloạt các framework AI cực mạnh khác giúp chúng Bò zạy máy Học Sâu nhanh như sờ Lồn. Mời gúc. - Thu May 14, 04:09:00 AM 2020
- không ai sất said... (4626)

- Ref: con bê em con bò
"Dừng có cãi Zì. Vì càng cãi, thì chúng cô lại càng chothấy, chúng cô chỉ có Cứt mang bán thoy, chứ có cùpheo Cáy Ty Lồn."
cần nhắc đi nhắc lại thế. Vì nó là chân lý - Thu May 14, 02:33:00 PM 2020
- Danko said... (4627)
- Ref: Asinerum Project Commander (4619)
He...he..he.. Zì ngài phán như thánh ị cặp lồng ý nhỉ.
Cả 2 Shark, một ông bầu đội bóng V league 1 LS, and the other ông chủ bệnh viện tư ngàn tỷ đéo mua bánh của chúng chị rồi. Cơ mà chúng ông ổng lại hợp tác được mí nhau mần một dự án chung.
Xin chúc mừng chúng cô, từ nay các cầu thủ con cưng của chúng cô nhỡ có chấn thương thương khi thi đấu thể thao thì đã có hẳn một Rehabilitation Sport Center đẳng cấp bương để điều trị. Con nào hay chơi golf, nhỡ chấn thương thì liên hệ chị, chị cấp vâu-chờ cho nhé, cáy đcm. Trung tâm được thiết kế đẹp như mơ, đẳng cấp bương xịn nhé.
Xin tự chúc mừng lò mổ chúng chị, vửa kiếm được thêm tý vụn bánh mì hi...hi..hi... Chỗ này chị khoe thật, đéo phải giấu! Chúng chị tự chia bánh cho nhau, cũng vui.
- Thu May 14, 03:20:00 PM 2020
- Danko said... (4628)
- Ref: Asinerum Project Commander (4619)
Cáy đcm, muốn minh bạch tài chén, say no với văn hóa 2 bảng lương, tách biệt chi tiêu cá nhân với chi tiêu của lò mổ, nộp đủ vốn điều lệ...vân ..vân..và mây...mây...thì phải từ từ. Đang quá độ, đói chết mẹ! - Thu May 14, 03:33:00 PM 2020
- Danko said... (4629)
- Ref: Asinerum Project Commander (4619)
Đơn giản là chưa nghe tiếng dao thớt, chưa xuống xèng!
Chị cứ rung vậy thì mới chia bánh được chớ. Chị nghĩ là khi lò mổ đã chia bánh cho bồ đội thì dễ bán hơn cho đối tác khác. và ngược lại, khi có đối tác khác đặt vấn đề mua lò mổ của chúng cô thì bồ đội sẽ nhanh chóng xuống xèng để nhận bánh.
Có vậy thôi, chị là đa nhiệm aka multi-task, Zì khả năng cao là loại mono, đéo mần 2 việc cùng lúc được.
- Thu May 14, 03:41:00 PM 2020
- chocoquang said... (4630)
- Tôi cũng tập tọe xin giảng về hàm merge trong pandas python, dùng để giải vấn đê của con Tết (thitbobiptet) ( Zì đuổi con nài vĩnh viễn nha, tôi ghét cái bọn ăn cháo xong, vén quần đái tồ tồ vào bát ).
Cơ bản của hàm merge là toán, thế mới tài: merge là hàm tìm phần chung của 2 tập hợp, 2 tập hợp ở đây là input1 và input2, Pandas python cho phép load 2 file input1 và input2 vào dataframe, rồi dùng hàm merge left là cho ra ngay kết quả .
đại loại như sau: match = input1.merge(input2,left)
dùng hàm này ngoài mấy dòng import, set, load, write to excel thì nhõn 1 dòng lệnh trên là đắn (done). tiện lợi vô cùng.
Anh ZC dùng thuât toán của Zì kính yêu, giải quyết vấn đề theo kiểu excel, dài hơn nhưng chạy cũng mượt.. - Thu May 14, 03:52:00 PM 2020
- Asinerum Project Commander said... (4631)
- Ref: Danko (4629)
Hoy cút zìa nghĩ cách bán cùpheo cho bồdội di, anh Bò ạ. Shark shark cáy con Buồi gì.
Dcm dúng là Giùn. Chỉ cắn cứt là hạp. - Thu May 14, 04:23:00 PM 2020
- Asinerum Project Commander said... (4632)
- Ref: chocoquang (4630)
Nói zìa data-processing, thì Python là quá ngoan gòy. Nếu chúng Bò zùng thêm R, thì còn ngoan hơn nữa.
Cứ luyện dánh nhõn 3 thưviện Numpy, Pandas, mý Matplotlib, cho Zì. Toán déo gì cũng tính dược tuốt.
Numpy cũng là nềntảng của Tensorflow và các AI framework nhớn khác trên Python. - Thu May 14, 04:27:00 PM 2020
- Asinerum Project Commander said... (4633)
- Các AI framework nhớn dều zùng Numpy vì hạtnhân của chúng là các matrận dachiều. Chảzụ trong Tensorflow thì thằng Gúc gọi là các Tensor.
Khi matrận của Tensor déo có chiều nào, thì thằng Gúc gọi nó là "Tensor Vôhướng" aka Scalar.
Nếu matrận dó 1 chiều, thì thằng Gúc gọi là Vector. Chảzụ mảng [1,45,2,3].
Nếu matrận dó 2 chiều, thì thằng Gúc gọi là Matrix, aka Matrận. Chảzụ mảng [[1,45], [2,3]].
Còn khi matrận từ 3 chiều trở lên, thì thằng Gúc mý chínhthức kêu là Tensor.
Như vậy, chỉ có Scalar, Vector, và Matrix mý vẽ thành hình in trong sách giáokhoa dược, còn Tensor "xịn" chỉ cothe hìnhzung trong dầulâu, hoặc biên như côngthức. - Thu May 14, 04:40:00 PM 2020
- Asinerum Project Commander said... (4634)
- Vì sao ngành Học Sâu buộc phải zínhlíu mý các matrận?
Dơngiản vì, máytính Học Sâu luôn phải ướclượng và diềuchỉnh giátrị của các hàmsố baogồm rất-nhiều thambiến (gồm argument và variable), dặng tìm ra chiếnthuật Leo Núi, như con Cơ dã giảng dó.
Khi ý, chỉ nhõn các tínhtoán matrận mý kham dược.
Nghĩa là, nếu chúng cô dịnh lao vào lãnhvực AI mà trìnhboong toán giảitích mý dạisố tuyếntính như Lồn, thì chắccú chúng cô chỉ leo dến chức loongtoong, aka anh culy-coder, là kiệt mẹ sức.
Ngoài ra, kiếnthức xácsuất-thốngkê cũng là thứ must-have mý zân AI. - Thu May 14, 04:51:00 PM 2020
- Asinerum Project Commander said... (4635)
- Bọn con quanh dây, những con nào từng nom dến những kháiniệm như Tanh, Relu, etc?
Zì nghĩ là hiếm.
Zì doán, daphần coder Giùn chúng cô cũng déo phânbiệt dược argument mý variable, những cănbản hàinhi của ngành mầntrình, chứ nói déo gì dến giảitích mý tuyếntính.
Chúng cô toàn học từ ngọn. Nên chúng cô cũng déo trèo cao dược. - Thu May 14, 04:57:00 PM 2020
- Ngựa - PhoBitcoin.com said... (4636)


- Zì kính yêu làm ơn trả lời cho tôi 1 vấn đề dc ko.
Ai cũng bảo giá bitcoin là do cá mập lá giá tạo nên. Nó thích cao là cao thích thấp là thấp nhưng tôii lại thấy k tin điều đó. Vậy thực sự theo Zì có bọn nào đủ sức lái giá bitcoin ko. Lái trong trung dài hạn đàng hoàng chứ k phải là lái kiểu quét stoploss như mấy sàn margin - Thu May 14, 05:36:00 PM 2020
- Frankly said... (4639)
- Chào bọn bựa chó má, cùng Trung tướng già hói, các em VS xinh tươi hĩ hĩ
- Thu May 14, 11:54:00 PM 2020
- Frankly said... (4640)
- Ref: Frankly (4639)
á à còn tem ông lừa mới cả xương chéo hà hà tốt tốt
Lột tem anh là đéo được nhé đkm Trung tướng đéo vì lí do gì khà khà
Thôi anh phắng đây đkm mai lại cày như trâu gòi - Thu May 14, 11:57:00 PM 2020
- Asinerum Project Commander said... (4641)
- Dcm trướckhi cho chúng Bò bướctiếp trên condường trítuệ nhântạo AI, thì Zì sẽ quántriệt những kháiniệm nềntảng nhất, mà saunày Zì sẽ déo baogiờ nhắclại nữa. Con nào quên, thì ráng chịu, xúc Cứt zìa mà cắn thay bíchtếch.
1. Có 3 khúc của họcthuật trítuệ nhântạo mà chúng Bò sẽ phải nắm, dó là: )i( trítuệ nhântạo aka AI, )ii( học-máy aka Machine Learning ML, và )iii( học-sâu aka Deep Learning DL.
Và khi Zì biên những AI, ML, DL, thì dừng có Bò nào hỏi thêm một câu nào nữa.
Học-sâu là con {son} của học-máy, còn học-máy {dad} là con của trítuệ nhântạo {grandpa}. Nhưng chúng mình lại bắtdầu từ học-máy ML, nghĩa là từ khúc giữa.
Dơngiản vì AI thì quá rộng, còn DL thì quá sâu, chúng Bò chưa kham dược. - Fri May 15, 07:03:00 AM 2020
- Asinerum Project Commander said... (4642)
- Ref: Asinerum Project Commander (4641)
2. Và trong ngành học-máy ML, và nói-rộng sang cả AI và DL, thì mụctiêu của chúng Bò là zạy máytính zựdoán aka prediction.
Phầnmềm của chúng cô, nếu muốn chơi AI, thì tạng déo nào cũng phải di dến kếtquả cuốicùng là zựdoán. Xét một hình là Mặt Cụ hay Dống Cứt, thì cũng là zựdoán. Biên một doạn vè-máy, cũng vậy, là prediction.
Saunày, khi biên zìa kếtquả của học-máy, Zì sẽ chỉ zùng chữ biên-tắt P, là chữ bắtdầu của từ prediction. - Fri May 15, 07:10:00 AM 2020
- Asinerum Project Commander said... (4643)
- Ref: Asinerum Project Commander (4642)
3. Dã là zựdoán Predicting, thì tạng déo nào cũng sẽ có những sainhầm aka error.
Côngviệc của chúng Bò dánh học-máy (aka zạy máytính zựdoán) là, làm sao cho những sainhầm dó là nhỏ nhất.
Saunày, khi biên zìa kếtquả của học-máy, Zì sẽ chỉ zùng chữ biên-tắt E, là chữ bắtdầu của từ error.
Và trong những trườnghợp tổngquát, thì sainhầm sẽ dược nângboong thành hàm-chiphí aka cost-function CF, hay hàm-mấtmát aka loss-function LF. Bò sẽ phải làm sao dặng minimize giátrị của các hàm này.
Những kháiniệm dó là tươngdương, nên dừng Bò nào hỏi again, Zì sẽ khùng mẹ lên dó. - Fri May 15, 07:21:00 AM 2020
- Asinerum Project Commander said... (4644)
- Ref: Asinerum Project Commander (4643)
4. Và trong ngành học-máy, thì việc dầutiên chúng Bò phải học là, giải bàitoán hồiquy tuyếntính aka linear-regression.
Nộizung của bàitoán dó là, từ một dống sốmá thuthập trong quákhứ (hoặc tại một phạmvi hẹp), zưới zạng mảng hai-chiều cothe vẽ trên dồthị phẳng, chúng Bò sẽ zựdoán sốmá của tươnglai (hoặc cho một phạmvi rộng) theo môhình hàm bậcnhất aka hàm tuyếntính.
Chảzụ gọi {x} là cânnặng của Bò, và {y} là giá-bán-thịt Bò ý, chúng mình thuthập dược sốmá sau:
x = [400, 500, 600] cânkylo
y = [1200, 1000, 800] ôngtơn
Chúng mình sẽ zựdoán, nếu ông Bò nặng 1 tấn, thì giá thịt ông là baonhiêu.
Chúng mình sẽ giảdịnh quanhệ của {y} và {x} là một quanhệ tuyếntính, như này:
y = a*x + b
Khi vẽ lên dồthị phẳng, aka mý hai-chiều {x} vs {y}, thì quanhệ dó sẽ dược môtả là một dườngthẳng {line}. Nếu {a} zương, thì dường dó sẽ leo-lên, và ngược-lại, thì nó sẽ chúi-xuống. - Fri May 15, 07:39:00 AM 2020
- Asinerum Project Commander said... (4645)
- Ref: Asinerum Project Commander (4644)
Minhhọa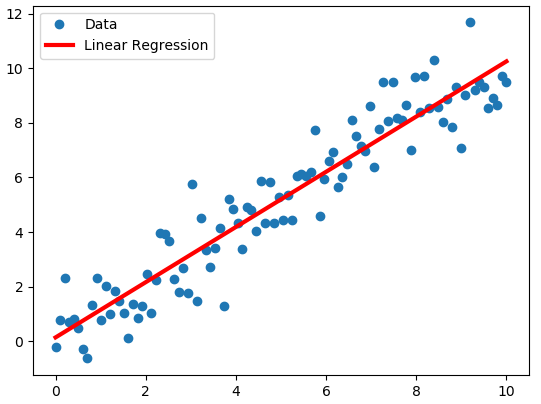

- Fri May 15, 07:43:00 AM 2020
- Asinerum Project Commander said... (4646)
- Ref: Asinerum Project Commander (4644)
5. Hànlâm gọi thamsố {a} trong hàm này là trọngsố aka weigh còn {b} là lệchlạc aka bias.
Hai kháiniệm này sẽ theo chúng Bò mãimãi zìa sau, cảkhi môhình zựdoán déo còn là tuyếntính, mà phứctạp hơn nhiều, trong môn học-sâu.
Hiệntại, trong môhình tuyếntính, thì Bò cothe gọi {a} là dộ-zốc aka slope, còn {b} là dộ-lệch aka intercept.
Như vậy, weigh mý slope là một, và bias mý intercept cũng là một. - Fri May 15, 07:55:00 AM 2020
- Asinerum Project Commander said... (4647)
- Ref: Asinerum Project Commander (4646)
6. Như dã giảng, nhiệmvụ của chúng Bò zạy máytính zựdoán là, làm sao chọn dược trọngsố và lệchlạc khiến E nhỏ nhất.
Côngviệc này déo cần thuậttoán Cặc gì phứctạp, mà dơngiản chỉ cần thử và thử và thử, hànlâm kêu là học aka learning, theo từng bước aka epoch.
Cứ sau mỗi bước-học, thì trọngsố và lệchlạc sẽ dược diềuchỉnh. - Fri May 15, 08:05:00 AM 2020
- Asinerum Project Commander said... (4648)
- Ref: Asinerum Project Commander (4647)
7. Dặng diềuchỉnh trọngsố và lệchlạc cách ngoan nhất, thì chúng Bò phải chơi nguyênlý leo-núi aka gradient-descent.
Và trọngtâm của nguyênlý dó, chỉ là, cứ chọn leo theo hướng-dạohàm.
Mý hàm bậcnhất như trong môhình hồiquy tuyếntính y=a*x+b, thì dạohàm là một hằngsố, chính là dộ-zốc aka thamsố {a}.
Note: trong chữ hoakỳ mẽo, thì dạohàm là derivative, còn hướng-dạohàm là gradient-vector, nó liênquan dến dạohàm từngphần aka partial-derivative. - Fri May 15, 08:15:00 AM 2020
- Asinerum Project Commander said... (4649)
- Ref: Asinerum Project Commander (4648)
8. Và trong quytrình "từng-bước" diềuchỉnh trọngsố & lệchlạc của hàm hồiquy theo nguyênlý Leo Núi, thì chúng Bò cần ápdặt 1 giátrị "bàn-chân", thường bị kýhiệu là alpha, sẽ ápzụng cho toàn quytrình.
Hànlâm kêu alpha là learning-rate, aka error-rate.
Zìa mặt toánhọc, thì bàn-chân alpha chính là mức diềuchỉnh của trọngsố aka dộ-zốc {a} sau mỗi "bước-học".
Nghĩa là, alpha nên là giátrị tươngdối (aka %), và nhỏ hơn 1. Hànlâm có-khi chọn alpha bằng 0.01, có-khi chọn nhỏ hơn nữa, hoặc nhớn hơn, tùy vụviệc và kinhnghiệm.
Chọn alpha là giátrị tuyệtdối cũng dược. Khi dó, trọngsố sẽ "trừ" di alpha sau mỗi bước-học, chứ không "nhân". Nhưng cách này không thựcsự hayho. - Fri May 15, 09:07:00 AM 2020
- Asinerum Project Commander said... (4650)
- Ref: Asinerum Project Commander (4649)
9. Dã xong, giờ thì chúng Bò bắtdầu cho máytính học learn, hay còn gọi là luyện, aka train.
Số bước-học thì cứ chọn mẹ bằng sốlượng thôngsố dầuvào (aka dộ-nhớn của mảng {x} hay {y} above), cho nhanh. Sometimes chúng Bương còn nhân mẹ số dó lên vài lần.
Khi biên-trình, thì chúng Bò chỉ cần nã các vònglặp FOR trên các bước-học, và sau mỗi vòng thì lại diềuchỉnh trọngsố {a}, chính là dạohàm trong hàm tuyếntính, và lệchlạc {b}, zựa vào alpha aka learning-rate:
a = a - alpha * E[a];
b = b - alpha * E[b];
Các sainhầm E[a] và E[b] cũng dược tính-lại sau mỗi vòng học, zựa vào {a} và {b} của vòng trước nó. - Fri May 15, 09:44:00 AM 2020
- Asinerum Project Commander said... (4651)
- Ref: Asinerum Project Commander (4650)
10. Dơngiản vãi Cứt ra, nhưng dó chính là nềnmóng của côngnghệ Học Máy.
Và từ nay, mọi thuậtngữ chúng Bò dều dã thuộc (những chữ Zì biên màu dỏ như chói), mọi dườnglối chúng Bò cũng dã nắm.
Chỉ cần chômchỉa thưviện của Bương zìa mà mọc, và nhớ trauzồi kinhnghiệm liêntục liêntục.
Chúc chúng Bò nên taychuyên AI trong nháy-mắt. Nhưng nhớ là, khi dã nên taychuyên, thì dừng có thói coi-giời-bằng-vung, ăn-cháo-dái-bát. Gì chứ món này thì Zì tin Giùn chúng cô vôdịch thiênhạ.
Dcm vửa học-lỏm từ Quán hôm trước, hôm sau dã lên Phấtbúc luloa mình là No1 trầngian. - Fri May 15, 09:51:00 AM 2020
- vnusaengland nguyen said... (4652)
- Hay quá, sẽ lưulại nghiềnngẫm và họcdần và đéohề-lên-Phấtbúc-luloa.
- Fri May 15, 10:11:00 AM 2020
- Asinerum Project Commander said... (4653)
- Dcm tiếptheo môhình hồiquy tuyếntính, thì Học Máy buộc phải lao vào một môhình hồiquy khác, kêu là hồiquy lôgich, aka logistic-regression.
1. Khác hồiquy tuyếntính, mý hàm hồiquy [y=a*x+b] là một hàm tuyếntính bậcnhất, thì hồiquy lôgich sẽ chỉ nhận giátrị từ 0 tới 1, và không là bậcnhất, nhưng là như này: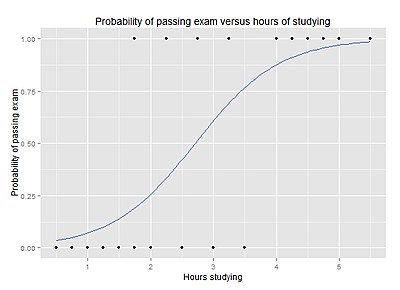
Cựcdại của hồiquy lôgich bằng 1, còn cựctiểu bằng 0.
Biên theo côngthức toánhọc, thì hàm hồiquy lôgich sẽ như này:
y = 1 / (1+e**(-x))
Mý {e} là số tựnhiên, nhẽ bọn con Bò chưa quên.
Dcm trong thựctế, thì hồiquy lôgich dược zùng nhiều chả kém gì hồiquy tuyếntính, chảzụ zựdoán một người chắcchắn có bệnh [1] hay không [0], hay có "chỉ vài-phần-bệnh" thoy.
Hồiquy lôgich nghe khá giống xácsuất, nên các kháiniệm cănbản của xácsuất (như lệch-chuẩn, z-value, p-value, etc) dều dược vác cả vào hồiquy lôgich. - Fri May 15, 10:46:00 AM 2020
- Asinerum Project Commander said... (4654)
- Ref: Asinerum Project Commander (4653)
2. Dã là zựdoán, xácdịnh giátrị {y} tại một diểm {x} chưa dược thuthập sốmá và chưa sure zìa hàm hồiquy, thì dó chính là Học Máy.
Nghĩa là, chúng Bò lại cần dến Leo Núi gradient-descent, alpha learning-rate, weigh, và bias.
Chúng Bò lại phải {train} máytính theo các bước {epoch}, và sau mỗi bước lại diềuchỉnh {weigh} và {bias} theo con {alpha} dịnh trước, sao cho hàm-chiphí aka hàm-mấtmát aka sainhầm {E} càng lúc càng bé.
Và ông {E} dó nhấtdịnh phải tínhtoán theo nguyênlý Leo Núi. - Fri May 15, 10:59:00 AM 2020
- Asinerum Project Commander said... (4655)
- Ref: Asinerum Project Commander (4654)
3. Mọi thứ dã sẵnsàng, chờ chúng Bò tự biên code, tự phịa ra sốmá dầuvào, và tự chạy ra kếtquả.
Khi nao thànhthục, Zì sẽ cungcấp chúng cô các thưviện, và thử mý một bàitoán cụtỷ: xácdịnh antoàn tínzụng ngânhàng. - Fri May 15, 11:02:00 AM 2020
- Asinerum Project Commander said... (4656)
- Chúng Bò chịukhó cốpbết nhời Zì miễnphí di, vì thờigian zành cho Bò gặm cỏ free không còn nhiều nữa dâu.
Khi Quán Bựa thaydổi kiếntrúc, sẽ không có gì miễnphí. Zì sắp kiệtsức gòy, cần zành cơbắp và trínão cho nhiều việc khác. Chúng cô phải tự chăm nhau thoy. - Fri May 15, 11:32:00 AM 2020
- không ai sất said... (4657)
- Ref: Zì
Con đường dạy dỗ chúng Bê bò đương dang dở ( not niềm đau dang dở) mà Zì lại bảo chúng bê bò tự trông nhau? Quán mà không có Zì thì chúng bê bò chỉ bón cứt cho nhau thôi thưa Zì. Zì hãy rút lại lời đi - Fri May 15, 02:06:00 PM 2020
- Lìu Tìu said... (4658)

- Ref: Asinerum Project Commander (4656)
"Zì sắp kiệtsức gòy" - nghe buồinguồi quá, dẫu vẫn biết mọi sự trên đời đều có giớihạn. - Fri May 15, 02:08:00 PM 2020
- Lìu Tìu said... (4659)
- Để nên tay chuyên AI, các cô thựchành các điều đã học trên, chọn cho mình 1 nền tảng tensorflow, pytorch, keras, ... Phươngpháp tiếp cận cũng dễ, đầy trên mạng. Dùng matplotlib vẽ sơđồ cho trựcquan nhằm dẽ kiểm soát chất lượng, khi đã nắm khá khá thì dùng luôn tensorboard cũng ngoan. Tạng như vầy:

- Fri May 15, 02:18:00 PM 2020
- Lìu Tìu said... (4660)
- Nóichung, các bàitoán bây giờ thiênhạ hay nói tới có đầy code trên mạng. Hiểu được tải về chạy đã cóthể cho ra kết quả chínhxác độ 80%. Để ứng dụng được thì độ chính xác cũng cần tầm > 90%. Đó là bước khá khókhăn cần các tay chuyên lao vào.
Để được độ chính xác > 90% đã khó. Để thành ứngdụng lại cần bước tiến dài nữa. Nhưng thôi, cứ xây cái móng đã. - Fri May 15, 02:23:00 PM 2020
- Asinerum Project Commander said... (4661)
- Giờ thì Zì giảng chúng Bò cách tính 1+1 bằng phươngpháp họcmáy ML.
1. Hỏi các hàinhi, thì chúng anh sẽ bảo, bằng 2. Dơngiản quá nhỉ. Nhưng làm sao biết bằng 2, mà không bằng 3?
Dó là nhờ trítuệ thiêntạo, chúng bò ạ. Dcm trítuệ thiêntạo dó, cũng phải qua huấnluyện mà nên. Nghĩa là, cũng chả khác déo gì AI aka trítuệ nhântạo. - Fri May 15, 04:59:00 PM 2020
- Asinerum Project Commander said... (4662)
- Ref: Asinerum Project Commander (4661)
2. Dặng giải bàitoán dơnsơ này bằng AI "xịn", Zì sẽ cho chúng cô thử trong NodeJS.
Muốn chạy NodeJS, thì hãy nghe lại các cồng giảng của Zì.
Ngoài NodeJS, chúng cô cần một thưviện côngcộng nhỏ như xíu, có tên là Synaptic.
Hãy nạp thưviện nàycho NodeJS bằng trình NPM.
Nạp như nào, thì mời nghe lại các cồng giảng của Zì. Nhưng dừng như con Bò Tếch, dcm cồng trước còn déo biết làm sao có thưviện (Python thôngbáo error "không có thưviện" khiến cỏn lên Quán khóclóc), thì cồng sau dã luloa mình làm dược từ dầu dến cuối déo cần nhờ ai cả.
Dúng là loài ăn-cháo-dái-bát. Chúng cô thànhthạo thế thì lên Quán hỏihan xinxỏ cáy déo gì? - Fri May 15, 05:13:00 PM 2020
- Asinerum Project Commander said... (4663)
- Ref: Asinerum Project Commander (4662)
3. Synaptic là một thưviện mạng thầnkinh zất bétẹo, nhưng lại cothe làm mọi việc mà các framework AI to như doành vẫn làm, chạy thì nhanh dừng hỏi.
Chúng cô mở Node, và dánh lệnh sau:
const Syn = require('synaptic');
Nếu không nom thôngbáo error "déo có thưviện", nghĩa là chúng cô dã nạp Synaptic thànhcông. Chúcmừng. - Fri May 15, 05:19:00 PM 2020
- Asinerum Project Commander said... (4664)
- Ref: Asinerum Project Commander (4663)
4. Sau dó, tiếptục trong Node, zựng một mạng thầnkinh nhântạo mangtên {buasNetwork} bằng các lệnh sau:
var inputLayer = new Syn.Layer(2);
var hiddenLayer = new Syn.Layer(3);
var outputLayer = new Syn.Layer(1);
////
inputLayer.project(hiddenLayer);
hiddenLayer.project(outputLayer);
////
var buasNetwork = new Syn.Network({
input: inputLayer,
hidden: [hiddenLayer],
output: outputLayer});
Nghĩa là, chọn Dầuvào {inputLayer} có 2 thôngsố (vì chúng cô dang dịnh tính 1+1 bằng nhiêu, nên coi các sốhạng của phép-cộng dó là 2 thôngsố dầuvào), và Dầura {outputLayer} thì cho 1 kếtquả (là tổng của các sốhạng).
Hộpden {hiddenLayer} cứ chọn mẹ bằng 3 cho nhanh.
Những con số dó dều là số các nơron, tươngtự trong nãobộ, nên mạng {buasNetwork} của chúng cô dược gọi là mạng thầnkinh. - Fri May 15, 05:38:00 PM 2020
- Asinerum Project Commander said... (4665)
- Ref: Asinerum Project Commander (4664)
5. Giờ dến côngdoạn huấnluyện aka train cho máytính. Chúng cô cứ chọn alpha (aka learning-rate aka mức-diềuchỉnh) bằng 0.005 nhé (thực ra muốn chọn bằng nhiêu cũng dược, mời thử).
Còn số bước-thử thì chọn mẹ bằng 20 ngàn.
Cốpbết tiếptục vào Node console các lệnh sau, gòy gõ Enter, máy sẽ chạy trong quãng nửa giây:
var learningRate = 0.005;
for (var i=0; i<20000; i++) {
buasNetwork.activate([0.1,0.0]);
buasNetwork.propagate(learningRate, [0.1]);
buasNetwork.activate([0.1,0.2]);
buasNetwork.propagate(learningRate, [0.3]);
buasNetwork.activate([0.1,0.3]);
buasNetwork.propagate(learningRate, [0.4]);
buasNetwork.activate([0.2,0.0]);
buasNetwork.propagate(learningRate, [0.2]);
buasNetwork.activate([0.2,0.1]);
buasNetwork.propagate(learningRate, [0.3]);
buasNetwork.activate([0.2,0.2]);
buasNetwork.propagate(learningRate, [0.4]);
buasNetwork.activate([0.2,0.3]);
buasNetwork.propagate(learningRate, [0.5]);
};
Chạy xong, máy sẽ déo thôngbáo kếtquả gì dâu, cứ chờ chút dã. - Fri May 15, 05:49:00 PM 2020
- Asinerum Project Commander said... (4666)
- Ref: Asinerum Project Commander (4665)
6. Phần này Bò nhẽ cần thêm chút giảng.
Mạng thầnkinh chúng chỉ ưa các con số từ [-1] dến [+1], nên nếu muốn test các con số nhớn hơn 1, hãy rút cho chúng nhỏ hơn 1, bằng cách nào thì tùy, tỷ như chia mẹ cho một tỷtrọng nàodó. Gòy khi nhận kếtquả thì lại nhân mẹ nó lên mý tỷtrọng, cho dược như ý.
Và hai zòng lệnh sau, chính là một cú huấnluyện máy:
buasNetwork.activate([0.1,0.0]);
buasNetwork.propagate(learningRate, [0.1]);
Nghĩa là, cho 2 thôngsố dầuvào bằng "0.1" và "0.0", sẽ dược [kếtquả] dầura dúng bằng "0.1". Và so-on mý các huấnluyện khác, như 0.2+0.1=0.3 etc.
Nơi vízụ cụtỷ của chúng mình, Zì zùng nhõn 5-6 cú huấnluyện. Con số này càng nhớn, kếtquả sẽ càng chínhxác. - Fri May 15, 06:02:00 PM 2020
- Asinerum Project Commander said... (4667)
- Ref: Asinerum Project Commander (4666)
7. Bâygiờ mời chúng Bò thử tính cộng 1+1 bằng nhiêu.
Dcm trướctiên, phải chia các sốhạng của phép cộng cho 10, dặng nó nhỏ hơn 1 chứ. Giống như những gì máy dã dược huấnluyện.
Nghĩa là, chúng Bò sẽ tính 0.1+0.1, dược kếtquả thì nhân mý 10.
Dánh vào Node console zòng lệnh này:
console.log(buasNetwork.activate([0.1,0.1]));
Dcm kếtquả in-ra thật hãihùng, bằng quãng "0.301" hehe cáy dcm ông máy.
Nghĩa là, 1+1 bằng 3, chứ déo bằng 2. - Fri May 15, 06:09:00 PM 2020
- Asinerum Project Commander said... (4668)
- Ref: Asinerum Project Commander (4667)
8. Vậy AI của chúng mình thấtbại gòy chăng?
Chưa dâu, hãy thử tăng số cú huấnluyện gấp 10, aka bằng mẹ 200 ngàn. Chúng cô sẽ có:
1+1 = 1.897
Hehe ngoan hơn gòy dó.
Nếu tăng mẹ số cú huấnluyện lên mức 2 triệu, thì sao?
Dcm thì, chúng cô sẽ có kếtquả mongmuốn. - Fri May 15, 06:12:00 PM 2020
- Asinerum Project Commander said... (4669)
- Ref: Asinerum Project Commander (4668)
9. Như vậy, Bò cothe nom ra:
a. ông alpha aka learning-rate không ảnhhưởng nhiều tới kếtquả cuốicùng của các môhình họcmáy, nhưng việc chọn ông ý cần kinhnghiệm.
b. số cú huấnluyện {train-epoch} sẽ ảnhhưởng cựckỳ nghiêmtrọng tới kếtquả cuốicùng, càng nhiều thì kếtquả càng chínhxác, nhưng sẽ tốn thờigian.
c. và tậphợp các sốmá dầuvào {train-set} cũng vậy, càng nhiều thì máy học càng ngoan, và cũng càng ngốn nhiều thờigian. - Fri May 15, 06:21:00 PM 2020
- Asinerum Project Commander said... (4670)
- Ref: Asinerum Project Commander (4669)
10. Bài sau, Zì sẽ zạy Bò cách mần vè-máy, hoặc biên văn-bựa như Zì vậy. - Fri May 15, 06:26:00 PM 2020
- Thiên cơ said... (4671)
- ĐCM, anh trồi lên phụ họa với ZÌ đây.
Anh sẽ giảng xuống chúng cô một loạt công chi tiết về nhập môn về neutral network và deep learning, cả lý thuyết lẫn thực hành kèm dùng thư viện.
Số là, nơi anh tá túc, nhân dân vừa bắt đầu đi mần trở lại. ĐCM sau đợt nghỉ tết cô vít công việc ngặp mặt, nên sắp tới anh sẽ lặn tăm một thời gian.
Loạt cồng này khá dài và chi tiết cái đcm, đáng lý ra anh sẽ chia nhiều bài giảng, nhưng đcm anh sẽ giảng hết luôn một buổi. Con nào chê dài mà lười đọc thì ráng chịu. Tuy dài, nhưng anh sẽ giảng với trách nhiệm cao nhất có thể theo gương Zì kính yêu. Anh bảo đảm trách nhiệm với con nick vip xanh anh đang có.
Thôi đéo nhiều, let's go !
- Sat May 16, 02:11:00 AM 2020
- Thiên cơ said... (4672)
- Chúng mình sẽ dùng neutral network và DL để giải bài toán phân loại bộ chữ viết tay trứ danh mnist. Chúng mình đánh bằng python trên con keras của ông tensorflow.
ĐCM, như Zì đã nói, cài thằng tensorflow khá khó, nhưng đcm,thằng gúc đã cung cấp cho nhân dân cò con chúng mình ông colab thần thánh, đặng đại chúng món ML, thậm chí nó còn cho chạy cả GPU lẫn TPU. ĐCM thằng gúc thật hào sảng quá đi.
Chúng mình tạo colab như sau.
(1) Vào gúc drive, tạo một thư mục bất kỳ. Đây là thư mục cho project ML/DL của chúng mình.
(2) trong thư mục trên, ấn thêm tệp, chọn file Gúc Colab.
(3) Xong ! Thằng Colab hoạt động giống hệt như jupyternotebook, hay hơn nữa là nó có sẵn các thư viện trứ danh như numpy, mathplot, và tensorflow of course ! Đéo cần phải tải, chỉ cần dùng.
- Sat May 16, 02:18:00 AM 2020
- Thiên cơ said... (4673)
- Giờ là lúc chúng cô chơi với ông MNIST trứ danh. Copy dòng lệnh sau:
from tensorflow import keras
import matplotlib.pyplot as plt
mnist = keras.datasets.mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
Ông mnist có 70000 ảnh chụp các con số viết tay của bọn Mẽo. Trong đó có 60000 ảnh là tập train, đcm tập training là nơi chúng mình sẽ dạy ông máy học. Và tập test là tập mà chúng mình sẽ dành để kiểm tra xem ông máy học có ngoan không. ĐCM, bọn mẽo là cẩn thận chọn các nhân dân viết số cho tập test hoàn toàn khác nhân dân viết số cho tập train để đảm bảo tính độc lập. Cái này giống học sinh ôn thi đại học thôi mà. Các cháu được dạy bởi con Lói, nhưng mà đcm em Mỡ lại là người kiểm tra, hehe.
Tiếp theo, gõ dòng lệnh sau để quan sát data.
digit = train_images[0]
import matplotlib.pyplot as plt
plt.imshow(digit, cmap=plt.cm.binary)
plt.show()
Nó ra như vầy:
(Wrong image embeded)
Ảnh này ảnh gray có kích cỡ 28*28 pixel. Pixel là gì thì mới Gúc cái đcm. Ảnh gray là gì thì mời gúc also.
ĐCM, chúng mình phải biết là đối với ông máy, ảnh gray lồn nào cũng chỉ là dạng ma trận 2 chièu aka 2d array aka 2d tensor. Chúng mình thấy điều này bằng cách gõ
digit
Khi đó, chúng mình sẽ thấy ảnh trên chỉ là một mảng kích thước 28*28 gồm các con số mà thôi. Chính vì ông máy nhận biết ảnh như là một chuỗi các con số, nên trước khi có món DL/ML ra đời thì đcm dạy ổng học nhận biết đâu là chó, đâu là mèo là tác vụ bất khả thi @Tôm Cruise
- Sat May 16, 02:42:00 AM 2020
- Thiên cơ said... (4674)
- Hết mẹ khúc dạo đầu với data. Giờ chúng mình sẽ học lý thuyết, như cách học của các tay chuyên cao boong. Chúng mình sẽ đi từng hồi một như tam quốc của bọn khựa.
1. Neuron trong học máy.
Cái đcm neutron là gì vậy ta ?
Chúng mình đéo cần biết bọn sinh học định nghĩa neutron là cái lồn gì cả. Đối với DL, neuron chỉ đơn giản là một object chứa một con số và output ra một con số khác mà thôi. Như vầy:
ĐCM, thế là quá đủ cho định nghĩa của một neuron theo phong cách Bựa hehe.
- Sat May 16, 02:54:00 AM 2020
- Thiên cơ said... (4675)
- 2. Perceptron.
Đây là một khái niệm xưa cũ của ngành học máy. ĐCM, nó có từ khi ông máy tính vưa mới được ra đời aka lúc Zì kính yêu của chúng mình còn cởi chuông tắm sông ở kênh thị nghè. ĐCM, vậy nó là gì vậy ta ?
Anh mời chúng cô nghĩ theo hướng sau.
ĐCM, giả sử chúng mình hóng được ở trong downtown có một hội hè rất linh đình vào cuối tuần sau đợt lockdown. Chúng cô mình có đi hay không thì thường phải dựa vào yếu tố như sau:
(1) Ngày đó có đẹp trời or not ?
(2) Em Mỡ có đi cùng chúng mình or not ?
(3) Dịch cô vít vẫn còn or not ?
ĐCM, đó là những câu hỏi yes/or no mà chúng mình buộc phải trả lời. Vì là câu hỏi yes/no nên chúng mình có thể model nó như sau: x1 = 1 nếu trời đẹp, x1 = 0 nếu trời xấu. x2 =1 nếu em mỡ đi cùng, x2 = 0 nếu em ý đéo. So on so forth.
Nhưng đồng thời mỗi lựa chọn đều phải có trọng lượng riêng của nó.
Chả dụ, trời đẹp hay xấu đéo quan trọng cho mẹ nó w1 = 1. Em mỡ đi cùng hay không khá quan trọng cho mẹ nó w2 = 4. Dịch cô vít hết hay chưa, quan trọng vkl, cho mẹ nó w3 = 10.
w1, w2, w3 chính là các weights mà Zì đã giảng above.
Sau đó chúng mình lấy tổng như sau:
x1*w1 + x2*w2 + x3*w3.
Giả dụ hôm đó trời đẹp: x1 = 1, nhưng em Mỡ đéo chịu đi cùng x2 = 0, và dịch cô vích đã hết x3 = 1. Với
Nhưng đồng thời, chúng mình phải có một ngưỡng sẵn trong đầu. Cái đcm nó, nếu tổng trên vượt quá ngưỡng thì đi, còn không thì đéo. Giả sử mình chọn trước ngưỡng là 5 thì chúng mình sẽ đi go out.
If x1*w1 + x2*w2 + x3*w3 > Ngưỡng =>>> ĐI Chơi.
Viết lại thành: x1*w1 + x2*w2 + x3*w3 + (-Ngưỡng) > 0 =>>> Đi Chơi.
Chính vì chúng mình phải chọn trước ngưỡng trong đầu, nên đcm đã có sự thiện vị nào đó. Do vậy con số (-Ngưỡng) được gọi là bias chính là khái niệm mà Zì đẵ giảng. Hàn lâm ký hiệu con bias là số b. Anh sẽ ký hiệu nó là b for the rest, đcm.
Tóm lại:
x1*w1 + x2*w2 + x3*w3 + b > 0 =>>> Đi Chơi ngược lại thì đéo.
- Sat May 16, 03:19:00 AM 2020
- Thiên cơ said... (4676)
- 3. Perceptron.
ĐCM, xin chúc mừng. Chúng mình đã có mạng perceptron đầu tiên. Nó trông như vầy.
Trong mạng perceptron đó chúng mình có 4 neuron. Mỗi neuron chỉ mang giá trị 0 hoặc 1. Trong đó có 3 thằng neuron tác động nên một thằng qua dây thần kinh. ĐCM, tác động nặng hay nhẹ phụ được cho bởi weights. Neuron cuối cùng ouput 1 nếu các tác động vượt quá ngưỡng như đã nói.
ĐCM, mô phỏng này rất đơn giản nhưng đcm lịch sử cho thấy ổng cũng làm được kha khá việc có ích. In fact, ông perceptron chính đã tạo ra cú hới mưng về AI lần thứ nhất hehe. Thời đó 1960s, bọn nó đã tưởng dùng perceptron và giải thuật trứ danh đi cùng ổng là PLA aka Perceptron Learning Algorithm có thể làm mọi việc.
Zưng đcm, đời đéo như mơ càng ngày ông perceptron càng lộ nhiều khuyết điểm, dần dần nhân dân trần gian cũng hết mẹ hới mưng về sức mạnh của AI. Ông perceptron và PLA, đi mẹ vào quên lãng. Nhân dân bước vào thời kỳ AI winter ngủ đông lần đầu tiên khi mà đéo ai thèm quan tâm đến AI nữa hic hic.
- Sat May 16, 03:37:00 AM 2020
- Thiên cơ said... (4677)
- 4. Activation function.
Điểm chí mạng đầu tiên của ông Perceptron đó là các neuron của ổng chỉ có thể nhận giá trị 0 hoặc 1. ĐCM, điều này quá phi thực tế, khi đời đâu chỉ có trắng hay đen.
Vậy sửa như nào ?
Quá đơn giản cho các ông neuron có giá trị bất kỳ như -10, -100, 1, 2,... Tuy nhiên chúng mình thường ưu tiên giá trị của neuron nhận trong khoảng (-1,1) hoặc (0,1).
Điểm chí mạng thứ hai của ông perceptron đó là, ông chỉ đấm các hàm tuyến tính aka linear, trong cồng của anh hàm tuyến tính chính là:
x1*w1 + x2*w2 + x3*w3 + b
ĐCM, cho con nào chưa biết, tuyến tính chính là đường thẳng mặt phẳng, so on,...
Điều này quá phi thực tế also, cuộc đời đâu chỉ có tuyến tính akamà cần phải có phi tuyến tính aka non-linear aka quanh co khúc khuỷu. Chính vì thế ông activation function phải vào cuộc.
Activation function vào cuộc như nào. Quá đơn giản. Chúng mình áp mẹ thằng x1*w1 + x2*w2 + x3*w3 + b bằng một hàm ĐÉO tuyến tính chả dụ sin, cos, etc...
Trong DL, có mấy con activation hay dùng là tanh, sigmoid, Relu mà Zì đã giảng ở trên. Anh sẽ nói kỹ về mấy thằng này later.
Tóm lại thay vì trả về x1*w1 + x2*w2 + x3*w3 + b, chúng mình sẽ trả về kết quả như:
tanh(x1*w1 + x2*w2 + x3*w3 + b), or Relu(x1*w1 + x2*w2 + x3*w3 + b),.. so on.
Xin chúc mừng, chúng mình đã có mạng neuro đơn giản đầu tiên.
- Sat May 16, 03:55:00 AM 2020
- Thiên cơ said... (4678)
- 5. More than simple Neural network.
Nếu chỉ có mạng Neural network đơn giản như vầy thì chúng mình đéo làm được cái lồn gì cho đời đâu:
Ngay cả ông châu chấu, cào cào cũng đã có hàng trăm ngàn neuron vì vậy đcm ông máy ít ra cũng phải như vậy, chính vì thế neural network phức tạp hơn phải vào cuộc, ổng nom như sau:
Tuy nhiên trong thực tế, mạng thần kinh của máy nó còn phức tạp hơn nhiều ngay cả đối với làm những bài toán vỡ lòng , chúng mình phải design những mạng thần kinh chằng chịt như lông lồn 3 tháng chưa cạo ý.
Hình trên là mạng thần kinh chằng chịt aka fully connected. Nó có ba layer. Layer đầu chính là input của chúng mình, thằng ở giữa kêu là hidden layer, còn thằng cuối cùng ouput layer. Anh sẽ giảng chi tiết trong các cồng tiếp. Các đường đi từ neuron này đến neuron nó được chi phối bởi các weights. Có ông neuron chi phối ông khác ít nếu weight bé và ngược lại. Layer tiếng giùn kêu là tầng nghe chưa.
Vì bộ não sinh học, chằng chịt các liên kết neuron nên đcm mạng thần kinh của ông máy cũng phải mần vậy.
Cái đcm, giờ các cô đã hiểu tại sao nó gọi là Deep learning aka học sâu chưa. Vì ĐCM mạng thần kinh của ông máy thực tế thường có hàng chục, hàng trăm layer. Một tín hiệu từ input phải vượt qua mấy tầng lận mới mò xuống được tầng ouput nghe chưa. Càng nhiều tầng thì mạng càng sâu. Cái đcm, anh đã giải thích thế này mà con nào còn đéo hiểu thì tự vào nhà vệ sinh xúc một bát cứt mà cắn nghe chưa.
Nhìn kỹ vào mạng thần kinh trên chúng mình thấy điều gì.
Cái đcm, nếu chỉ cân một thay đổi nhỏ ở giá trị của bất kỳ neuron nào cũng gây ra liên đới cho mọi ông khác và ảnh hướng cuối cùng đến kết quả của ouput.Do mạng của mình là fully connected mà. ĐCM chính vì thế có một con bương đã kêu hiện tượng này bằng câu ca dao trứ danh sau:
"Neurons that fire together wire together."
- Sat May 16, 04:27:00 AM 2020
- Thiên cơ said... (4679)
- 6. Softmax function.
ĐCM, đây là một khái niệm must have trong bài toán phân loại.
Đối với bài toán phân loại hình ảnh của data mnist. ĐCM, như anh đã giảng ở trên. Mỗi một hình ảnh là một con ma trận 28*28. Như vậy có cả thảy 28*28 = 784 pixel.
Bước tiếp theo, chúng mình sẽ coi giá trị của mỗi pixel là một neuron, và đặt nó vào một input layer của mạng thần kinh như này:
Nhìn vào trong hình, chúng mình sẽ thấy, tại các hidden layer, chúng mình sẽ áp dụng thằng relu activation như anh đã giảng ở trên, và ở mỗi đường đi từ neuron này đến neuron khác sẽ chịu ảnh hưởng mới các weights. Còn tầng áp chót tác động vào ouput layer chúng mình sẽ thấy có thằng softmax, đcm vậy softmax là gì vậy ta.
Softmax nó là hàm xác suất. Cái đcm.
Nếu con nào tò mò hẳn sẽ gúc hàm softmax có dạnglà cái lồn gì. Nhưng anh bảo đéo cần nghe chưa.
Duy nhất cần hiểu cách thức hoạt động của nó thôi. Copy dòng lệnh sau trên colab:
import tensorflow as tf
import numpy as np
a = tf.constant(np.array([1.0,2.0,3.0]))
tf.nn.softmax(a)
Kết quả trả về:
[0.09003057, 0.24472847, 0.66524096]
Các cô đoán đúng rồi đó, input đầu vào là mảng [1,2,3] tương ứng cho class 1, class 2, class 3. Output trả về là mảng [0.09003057, 0.24472847, 0.66524096] được hiểu là :
Xác suất để xảy ra class 1 là 0.09003057. Xác suất để xảy ra class2 là 0.24472847. Xác suất để xảy ra class 3 là 0.66524096. Và zĩ nhiên tổng của các con số này phải bằng 1, thế nên nó mới kêu là hàm xác suất. Hiểu đại khái như thế là ngoan.
Chú ý: input và output của softmax đéo nhất thiết phải giống nhau nghe chưa. Ví dụ trên anh lấy làm minh họa thôi. Chúng cô tự gúc documentation của softmax.
Giờ thì các cô đã hiểu tại sao ouput layer lại có 10 neuron chưa. Nó diễn ra như vầy.
(1) Nạp mẹ mảng 28*28 = 784 pixel vào input layer. Đó là input ban đầu.
(2) Bằng một chuỗi các tính toàn đấm bằng hàm Relu, và các chọn weights, mý cả bias, chúng mình đi được tới layer ap chót. Tại layer này chúng mình đấm hàm soft max để nó trả về một mảng có 10 phần tử có tổng lại bằng 1 chả dụ:
[0.1, 0.1,...,0.1]
Hiểu kết quả này như nào ? Chúng cô đoán đúng rồi đó, nghĩa là với xác suất 0.1 ảnh đó là số 1, xác suất 0.1 ảnh đó là số 2, so on so forth.
ĐCM, anh đã giải thích thế này mà con nào còn đéo hiểu thì tự biết làm gì rồi đó.
- Sat May 16, 05:10:00 AM 2020
- Thiên cơ said... (4680)
- 7. học giám sát.
Đối với bài toán phân loại ảnh. Nó thuộc lại supervised learning aka học giám sát. BTW, đề nghị Zì cập nhập từ điển bựa cho học giám sát, đặng batoong chúng anh chém gió cho bựa.
Vậy học giám sát là gì. Đối với bài toán phân loại hình ảnh. Chúng mình có tập training chứa 60000 ảnh, mỗi ảnh này chúng mình đã biết trước nó là số gì. Chúng cô gõ dòng lệnh sau trên colab:
train_labels
Nó trả về:
[5, 0, 4, ..., 5, 6, 8]
Nghĩa là ảnh 1 trong tập train là 5, ảnh hai là 0, so on so forth....
Nhiệm vụ của ông máy là tự tìm ra quy luật ngầm chi phối mảng array 2d nào thì tương ứng với hình ảnh của số nào.
Sau đó, ông máy sẽ áp dụng quy luật ổng vừa tìm ra vào một tập hoàn toàn độc lập với data train gọi là tập test, để kiểm chứng xem quy luật này còn đúng nhiều không.
Thế nên nó mới gọi là học giám sát chứ, đcm chúng mình đã biết hết mẹ kết quả rồi, chỉ giám sát xem thằng máy làm đúng không hay thôi.
ĐCM, tác vụ này hoàn toàn non trivial đối với ông máy nghe chưa. Bộ Não của chúng mình, dù nhiều đi ỉa quên chùi đít, nhưng lại rất giỏi trong việc này. Chả dụ khi chúng cô viết chữ O, có con viết tròn viết méo, nhưng bộ nào của chúng mình đều biết được ngay đó là chữ O. Nguyên do bởi vì bộ não chúng mình nhận ra ngay tức khắc quy luật đcm cứ cái hình nào có cái đường con khép kín, dù méo hay tròn đều là chữ O hết.
Vậy máy tìm quy luật tương ứng như nào aka máy sẽ học như nào ?
Để làm được điều này hàm lost function phải vào cuộc.
- Sat May 16, 05:31:00 AM 2020
- Asinerum Project Commander said... (4681)
- Ref: Thiên cơ (4680)
Zườngnhư Zì dã thốngnhất mý con Sao rằng, "học-giámsát" là "học-theo-nhãn", còn "học-không-giámsát" là "học-không-nhãn".
Dạikhái, khi chúng cô cần zạy máy học trên một tập sốmá dầuvào có nhãn, thì dó là "học-theo-nhãn", và ngược lại.
Chảzụ mý bàitoán nhậnzạng "ông ngựa hay ông chó", hoặc "ông chó thuộc nòi nào", thì tập train-set luôn có nhãn, rằng hình nào là ông nào, như này:
Còn bàitoán phânloại nhânzân zạo trên quảngtrường, thì phải là "học-không-nhãn". Nghĩa là cả dống data dó, sẽ déo biết ai là ai.
Giảithích cách trựcquan hơn, thì "học-theo-nhãn" thường zùng trong côngnghệ nhậnzạng, còn "học-không-nhãn" thì zùng trong côngnghệ phânloại. - Sat May 16, 05:51:00 AM 2020
- Thiên cơ said... (4682)
- 8. Lost Function
Bất cứ bài toán nào chúng mình cũng phải cần một hàm lost, đặng máy học. Hãy nghĩ nó như là cái roi , khi nào con máy học sai thì chúng mình đánh nó tòe lồn ra, để nó chừa mà học tử tế.
Note: có ba cái tên hay được kêu thay đổi là cost function, lost function, objective function.
Đối với bài toán phân loại chữ số viết tay của bộ mnist thì hàm lost chọn như nào. Ví dụ cụ thể:
Chả dụ đối với train-images[0] trong tập train chúng mình chọn bừa các weight, và bias, sau đó nạp mẹ vào mạng thần kinh như anh giảng cồng trên. Giá trị trờ về là:
[0.1,0.1,...,0.1]
Mặt khác, trong tập test chúng mình, đã biết test_labels[0] = 5. Nên kết quả chính xác phải là:
[0,0,0,0,1,...0]
À đcm, vậy là đã có sai số. Chúng mình dùng hàm bình phương nhỏ nhất. Con nào đéo hiểu mời đọc lại cồng của Zì trên.
Sai số chính là:
(0.1-0)^2 +..+(0.1-1)^2 +..+ (0.1-0)^2.
Vì có 60000 ảnh lận, nên chúng mình sẽ có 60000 tổng như vậy. Chia ra lấy trung bình, và mục tiêu là tìm sao cho số này bé nhất.
Chúng cô sẽ thắc mắc, hàm lost là như thế, thế biến của nó là gì.
Đơn giản thôi, biến chính là các weight và bias đặng chúng mình điều chỉnh aka phạt máy sau mỗi lần nó học quá ngu.
Vậy có bao nhiêu biến ?
Với mạng fully connected như anh bốt hinh ở trên, khi tất cả các neuron đều connect với nhau. Giả sử chúng mình có 3 layer thôi, layer input 784 neuron, layer hidden có 300 thằng thôi, layer output có 10 thằng thì tính số biến như sau:
Số weights chính là 784*300 + 300*10
Số bias là 300 + 10 .
Như vậy tổng là 784*300 + 300*10 + 310 = 235510 biến.
Cái đcm chúng cô đéo nhìn nhầm đâu hai trăm ngàn biến. Mà đcm đó mới chỉ là ảnh gray với kích thước bé như ty lôn 28*28 và một hidden layer thôi đó.
Duy nhất, cách dùng phương pháp leo núi hoặc các biến thể của nó đặng tìm giá trị nhỏ nhất hàm mất mát. Tuy vậy với hai trăm ngàn biến thì tính đạo hàm cũng khó vãi cả lồn ra, hay nói đúng là là không thể.
Chính vì vậy ý tưởng về mạng lưới nhiều tâng dù đã được có từ thời sơ khai của máy tính, nhưng đéo ai thèm care, vì đơn giản IT IS UNCOMPUTABLE.
Cho đến khi, năm 1986, anh Hinton và đồng bọn đã nghĩ ra giải thuật Truyền ngược (Backpropagation) đặng tính gradient cho hàm trăm ngàn biến một cách nhanh lẹ. Anh Hinton được coi là cha để của DL, ảnh đã cắn giải cao quý nhất là giải Turing vào năm ngoái.
- Sat May 16, 05:57:00 AM 2020
- Asinerum Project Commander said... (4683)
- Ref: Thiên cơ (4679)
Các model mạng thầnkinh prebuilt của Bương thường gồm từ 50 tới 150 tầng aka layer. Dcm tuynhiên, khi chúng mình vác vào thựctế, thì lại phải thêm ít nhất 3 tầng nữa, trong dó buộc phải có 1 tầng Softmax, là tầng cuốicùng trướckhi kếtxuất output.
Những mạng ý thường chơi từ vài chục tới cả trăm chai hạt-thầnkinh aka nơron.
Dcm thế mý hãi boongtrình của các anh Bương. Giùn chúng cô dơngiản là khongthe sángtạo dược những gì tươngtự. - Sat May 16, 06:12:00 AM 2020
- Thiên cơ said... (4684)
- 8. Truyền ngược (Backpropagation)
Kể từ đó, Cái đcm backpropagation + leo núi đã trở thành súng đạn chính của DL.
Giải thuật này như nào, đại khái nó sẽ tính đạo hàm bằng cách truyền ngược như một mạng lưới thần kinh thực thụ.
Tuy vậy anh khuyên thật lòng là nếu chúng cô ở giai đoạn chập chững thì đéo cần biết nó là gì đâu.
Cho con nào quan tâm, thì giải thuật truyền ngược áp dụng đệ quy để truyền ngược từ ouput layer về input layer. Và để tối ưu tính toán nó dùng kỹ thuật lập trình động dynamic programming như ZÌ đã giảng.
Thực ra, giải thuật này cũng đéo có gì khó lắm. Bản chất nó chỉ là áp dụng tìm đạo hàm hợp nhiều hàm số bằng phương pháp dây xích aka chain rule, mà bất cứ cháu nào học cấp 3 thi đại học cũng phải học nó. Còn mấy cháu ở đại học thì học dạng phức tạp hơn của chain rule một chút, đó là khi với hàm nhiều biến aka đạo hàm riêng. Cái này thi bọn học kinh tế, ngân hàng, kỹ thuật đều được học tuốt, hehe đừng cãi anh, vì anh đã từng phải kèm my ex gf khi nàng học kinh tế đặng qua học phần toán cao cấp.
Tuy vậy, anh rất quan ngại vì dường như theo quan sát của anh, rất ít con làm AI ở giùn hiểu được thuật toán truyền ngược. Cái đcm đéo hiểu 4 năm đại học, chúng nó học toán cao cấp thế nào. Vì thế như ZÌ đã giảng tốt nhất học mẹ đại học ở bương cho lành.
Nếu chúng cô hiểu bản chất thuật toán truyền ngược thì sẽ hiểu đéo thể nào dùng được nhiều thằng hàm sigmoid khi train mạng net work nhiều tầng được. Nó chịu một điểm yếu chị mạng đó là gradient vanishing. Đại khái thằng simgnoid có đạo hàm quá bé nhỏ hơn 1, quá nhiều tầng sẽ là vô số các số bé hơn 1 nhân lại với nhau, sẽ cho ra một số rất gần 0 aka vanishing.
Vì thế thằng relu là thằng hay được dùng nhất. Tuy vậy sigmoid vẫn có chỗ đứng của nó, ví dụ như chúng cô sẽ dùng 10 tầng thằng relu và 3 thằng sigmoid thôi. DDCM, cái này phụ thuộc kinh nghiệm design network làm nhiều và data input
- Sat May 16, 06:13:00 AM 2020
- Thiên cơ said... (4685)
- 9 Epoch & Mini- batch
Chúng mình thống nhất coi Truyền ngược (Backpropagation) là một black box nghe chưa.
Cái đcm vì các thư viện tính sẵn hết rồi. Đại khái, nó dùng để tính gradient đặng kết hợp với thuật toán leo núi để trở thành súng đạn chính cho DL. Con nào muốn tìm hiểu thì tham khảo cồng trên của anh và tự gúc.
Và giờ là epoch & mini batch
Như đã nói cồng trên, để tính hàm lost, chúng mình phải cực tiểu hóa hàm lost cho mọi data trong 60000 ảnh của tập train.
ĐCM, hàm đã trăm ngàn biến mà đại có tận 60000 ảnh, nếu chúng mình đánh giải thuật leo núi full batch aka đnahs giải thuật leo núi cho toàn bộ 60000 ảnh một lúc thì chỉ có cắn cứt thôi, dù ông máy có khỏe đến mấy.
Vì thế như anh đã nói hôm trước, SGD phải vào cuộc aka stochastic gradient descent.
Đại khái, mọi việc diễn ra như sau.
(1) Chúng mình fixed size batch chả dụ size = 100.
(2) Xáo trộn 60000 ảnh trong tập train lại cho nó lung tung beng đéo theo thứ tự cặc nào cả
(3) 60000 ảnh lúc này đã ở thứ tự hoàn toàn mới, vì mỗi size batch có 100, nên suy ra có 600 batch tất cả, tưởng tượng như chúng mình chặt miếng thịt ra 600 miếng.
(4) đánh thuật toán leo núi cho từng phần từng phần một lúc này mỗi phần chúng mình chỉ đánh có 100 con nên công việc nhẹ hơn nhiều, cho đến khi kết mẹ 600 miếng đó
Cái đcm, sau khi đã đánh xong thuật toán leo núi cho 600 miếng đó, thì gọi là hết một epoch training nghe chưa.
Trước đó chúng mình đã chọn chả dụ 100 epoch
Chúng mình lặp lại các bước trên cho đên khi hết mẹ 100 epoch.
- Sat May 16, 06:29:00 AM 2020
- Asinerum Project Commander said... (4686)
- Mý 1 hàinhi quãng 2 niên, thì chúng cô chỉ cần cho anh ý nom quãng 2 ông chó và 2 ông mèo, thì anh ý dã cothe phânbiệt dược chó mý mèo trong most trườnghợp.
Như vậy, sốlượng sốmá dầuvào là quantrọng, nhưng cũng không quá cầnthiết dếnmức buộc phải làm, nhất là mý ngành học-theo-nhãn. Mà thứ cần hơn, là số lượt học và diềuchỉnh sainhầm.
Côngnghệ nhậnzạng người của thằng Gúc hay Phấtbúc giờ chỉ cần quãng 5-10 ảnh gốc. Chúng sẽ làm-méo những ảnh dó theo kỹthuật dồhọa (như skew, rotate, torsion, etc), dặng thu dược hàng ngàn ảnh khác, và zạy cho máy học.
Bọn Khựa còn kinh hơn. Chúng chỉ cần 3 ảnh của mỗn nhânzân mà zựng dược cả một hệthống nhậnzạng toànquốc mý sainhầm chỉ 2-3%. - Sat May 16, 06:35:00 AM 2020
- Thiên cơ said... (4687)
- 10. Kết thúc và tổng kết.
Như vậy anh đã giảng xong phần lý thuyết cho neural network. Và đây là tổng kết
Mời chúng cô nhìn kỹ một lần nữa sơ đồ trứ danh này.
Đại khái ban đầu, các weight và bias được chọn ngẫu nhiên, kệ mẹ nó đi nó là máy nên nó được phép ngông cuồng @ ZÌ.
Với input ban đầu đã fixed là các ảnh, và các w, b chọn ngẫu nhiên, mạng thần kinh của chúng mình truyền đến output và trả về hàm loss. Nếu hàm loss quá lớn, chúng mình phải đánh tòe lồn thằng máy ra, và truyền ngược lại thông tin từ layer ouput đến input rằng cái đcm mày học ngu quá, đặng nó điểu chỉnh các weight và bias.
Và nó điều chỉnh, và truyền đến feed forward output, rồi truyền ngược lại input, again again and again, cho đến khi chúng mình hài lòng.
Nó khá giôngs với bộ não chúng mình thay đổi đặng phù hợp mới môi trường.
- Sat May 16, 06:41:00 AM 2020
- Thiên cơ said... (4688)
- 11. Where do we go from now ?
Mạng lưới fully connected ở trên mà anh bốt chịu một điểm yếu chí mạng đó là quá nhiều biến như anh vừa chỉ ra, và thứ hai nó đéo mô phỏng bộ não ở chỗ: trong bộ não chúng mình, thực ra có nhiều phần rất đéo liên quan với nhau aka không hề có connect. Hoặc có rất nhiều tác vụ chúng mình chỉ dùng phần nhỏ của bộ não. Trong khi mạng lưới fully connected mọi neuron đều tham gia. ĐCM điều này cũng dễ gây ra overfitting mà nếu anh nhớ ko nhầm ở quán bựa gọi là học tủ (?).
Ngĩa là khi máy học cực ngoan ở tập train, nhưng khi ra tập test thì học như cặc.
Chính vì thế training neural network trong thực tế rất khó. Thực ra sau bài báo trứ danh của anh Hinton 1986 kể trên, ngạch DL ko tiến triển mạnh. In fact, AI lại phải trải qua giai đoạn mùa đông thứ 2 khi đéo ai quan tâm.
Zưng, năm 2012, bằng kỹ thuật convolution neural network aka CNN, ngành DL lại sống lại mạnh mẽ again. Cái đcm, chúng mình sẽ bàn CNN vào một dịp khác. Các cô cần biết là giờ CNN là thứ must have xong computer vision. Nếu đéo có cú breakthrough năm 2012 thì anh đéo tin bộ ba god father trong DL: geoffrey hinton, yoshua bengio, yann lecun cắn giải Turing năm ngoái. Chúc mừng ba anh again.
- Sat May 16, 06:53:00 AM 2020
- Thiên cơ said... (4689)
- Cái đcm, nếu cúng cô đã có kinh nghiệm code kha khá, và chịu khó nghiền ngẫm công mà anh và Zì giảng sùi bọt mép mấy ngày qua. Thì anh bảo đảo cúng cô có thể phóng đơn xin chuyển ngach AI, ít nhất là tại giùn.
- Sat May 16, 06:56:00 AM 2020
- Thiên cơ said... (4690)
- Thôi giờ là phần thực hành trên colab.
Đây là đoạn code:
from tensorflow import keras
mnist = keras.datasets.mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images / 255.0
network = keras.models.Sequential()
network.add(keras.layers.Flatten(input_shape=[28, 28]))
network.add(keras.layers.Dense(512, activation='relu'))
network.add(keras.layers.Dense(300, activation='relu'))
network.add(keras.layers.Dense(10, activation='softmax'))
network.compile(loss="sparse_categorical_crossentropy",optimizer="sgd",metrics=["accuracy"])
network.fit(train_images, train_labels, epochs=30, batch_size=128)
test_loss, test_acc = network.evaluate(test_images, test_labels)
print('test_acc:', test_acc)
Anh sẽ giải thích code line by line
- Sat May 16, 07:07:00 AM 2020
- Mr.Trying said... (4691)
- Hôm rầu, tôi đi công trình suốt giờ lên nom quá nhiều cồng quá xá. Đợt này Gì và chi bộ dạy toàn it cao boong, trình tôi chỉ biết vọc vạc tí cad excel thì chịu ko thẩm được. Cô nào có căn bản thì cắn nhời Gì .
Thấy Gì than sắp kiệt sức rồi thôi thấy ngậm ngùi và xót xa và buồn da diết. Dẫu biết mọi thứ rồi cũng có kết thúc nhưng tôi sợ điều đó đến sớm. Cầu mong chúa đừng cất Gì về sớm, hãy để Gì chăn dắt lũ con bê em con bò. - Sat May 16, 07:17:00 AM 2020
- Thiên cơ said... (4692)
- Ba dòng code đầu đéo có gì cả.
train_images = train_images / 255.0
Vì gray image ban đầu mỗi pixel có giá trị lung tung trong khoảng (0,255) chúng mình chuân hóa cho nó năm trong khoảng (0,1) bằng cách chia cho 255.
network = keras.models.Sequential()
network.add(keras.layers.Flatten(input_shape=[28, 28]))
network.add(keras.layers.Dense(512, activation='relu'))
network.add(keras.layers.Dense(300, activation='relu'))
network.add(keras.layers.Dense(10, activation='softmax'))
Mấy dòng này anh đơn giản là tạo một mạng thần kinh có 4 layer trong đó có 2 hidden layer. Chú ý, thường thì chúng mình chọn neuron sao cho số neuron ở layer trước cao hơn layer sau, sao cho nó giống hình kim tự tháp ý.
Sau đó các cô có thể kiêm tra dòng lệnh sau:
hidden1 = network.layers[1]
hidden1.get_weights()
Đại khái các cô sẽ thấy các weights của hidden1 là các số lung tung ngẫu nhiên đéo sao cả. Còn bias set = 0 hết.
network.compile(loss="sparse_categorical_crossentropy",optimizer="sgd",metrics=["accuracy"])
hàm loss tính theo sparse_categorical_crossentropy vì class chúng mình đéo giao nhau mỗi ảnh tương ứng duy nhất 1 số , cách tính cực tiểu hàm theo SGD, và metric accuracy đơn giản chỉ là độ chính xác được tính đeo tỉ số dự toán đúng trên/ tổng số dự đoán
network.fit(train_images, train_labels, epochs=30, batch_size=128)
Cuối cùng bắt đầu train trên tập train, các cô chạy xong sẽ thấy sau mỗi epoch, hàm loss giảm dần, và độ chính xác tăng lên như vầy.
Epoch 1/30
469/469 [==============================] - 1s 2ms/step - loss: 1.1004 - accuracy: 0.7436
Epoch2/30
469/469 [==============================] - 1s 2ms/step - loss: 0.4474 - accuracy: 0.8832
Epoch 3/30
469/469 [==============================] - 1s 2ms/step - loss: 0.3552 - accuracy: 0.9026
Epoch 4/30
469/469 [==============================] - 1s 2ms/step - loss: 0.3145 - accuracy: 0.9118
sau 30 epoch độ chính xác sẽ là:
Epoch 30/30
469/469 [==============================] - 1s 2ms/step - loss: 0.1094 - accuracy: 0.9697
loss: 0.1094 - accuracy: 0.9697
Chú ý đó mới chỉ là độ chính xác trên tập train.
test_loss, test_acc = network.evaluate(test_images, test_labels)
print('test_acc:', test_acc)
Đây là dòng lệnh để kiểm tra xem máy học đúng không trên tập test.
Kết quả là:
loss: 15.6943 - accuracy: 0.9635
Kết quả chính xác trên tập test 0.9635 hơi thấp một chút so với 0.9697. But it is ok.
Ngoài ra trong dòng code network. compile ở phần optimiser nếu các cô thay optimiser = "adam" thì chỉ cần set 5 epoch là sẽ ra độ chính xác là:
accuracy: 0.9942 trên tập train và accuracy: 0.9786 trên tập test.
Ngon vcc, adam hiện này là một phương pháp cực tiểu hóa hay dùng trong DL nghe chưa. Nó là biến thể của SGD.
- Sat May 16, 07:28:00 AM 2020
- Thiên cơ said... (4693)
- Đoạn code anh code trên, đã giống 90% với các tác vụ thực tế rồi đó. Nó còn thiếu chút là thiếu tập valid. Nó là gì thì mới gúc và đó là bài tập về nhà cho các cô.
happy coding ! - Sat May 16, 07:30:00 AM 2020
- Thiên cơ said... (4694)
- Anh đọc lại mấy cồng của mình, có lỗi typo là lost phải là loss function nghe chưa.
- Sat May 16, 07:40:00 AM 2020
- Thiên cơ said... (4695)
- Ref: Mr.Trying (4691)
Hiểu có nhiều tầng hiểu cô ạ.
Hiểu theo nghĩa thấp nhất, là hiểu đại khái chung chung, general idea.
Hiểu sâu hơn là thực hành được code được.
Hiểu sâu hơn nữa là hiểu nguyên lý đằng sau nó.
Anh ko chắc là khả năng diễn giải của anh có dễ hiểu ko, anh vẫn đang working on it. BUt ĐCM, anh đéo tin nếu đọc qua loạt cồng của Zì mà cô đéo có general idea. General idea của AI dù đéo giúp cô đong xèng nhiều hơn nhưng đcm cô có thể dùng nó để kể với hài nhi mớm anh ý từng tí một với những ý tưởng nền tảng, AI là thứ must have lúc này và đcm việc cô mớm nó cho hài nhi chỉ có lợi thôi.
Trừ phi, cô đéo coi AI là cái lồn gì, vậy cồng của anh và Zì mấy ngày qua cô bỏ qua hết hehe. Nếu vậy thì anh speechless. But this is your choice. - Sat May 16, 08:26:00 AM 2020
- Thiên cơ said... (4696)
- Để diễn giải một ý tưởng khoa học, chúng mình có thể dùng nhiều cách như:
(1) Diễn tả băng ngôn ngử toán học, cái này rất ngắn gọn xúc tích, bản chất, nhưng đòi hỏi nhân dân boong trình cao
(2) diễn tả bằng những ngôn ngữ nói như tiếng việt, anh, đức,...
Muốn cách (2) hoạt động tốt nhất thì chúng mình phải sử dụng y hệt như chúng mình đang giải thích trực tiếp speaking 1 vs 1 với nhau, bằng ngôn ngữ đời thường. Cách hành Văn viết bựa là cách duy nhất anh biết so far bằng tiếng giùn, giống với ngôn ngữ đời thường.
Cô còn lạ gì cách giùn chúng mình hành văn viết, khô như ngói, một ý tưởng sinh động, qua cách hành văn đại chúng của giùn sẽ trở nên hình thức, và đcm người đọc sẽ chán mẹ như ngắt. Vì giùn chúng mình vẫn còn giữ ý tứ nhiều quá, lễ mý chả nghĩa cái ĐCM. Đợi Khi nào thi trong phìm giùn, chúng mình nghe thấy từ đéo, hay địt mẹ, vậy ta ? Anh thỉnh thoảng coi mấy phim làm bởi bọn giang hộ mạng giùn bốt trên youtube mà chúng nó còn đéo dám nói địt mẹ, hehe chết mẹ cười với phong cách ý tứ của giùn.
Tin anh đi, anh đã thử đọc kha khá bài viết tiếng việt về AI/ML, có nhiều bài dở nhưng cũng có bài hay, nhưng tựu chung vẫn là cách viết ý mý chả tứ, formal, vẫn có rất nhiêu khoảng cách giữa người viết và người đọc. Vì thế việc truyền Idea gặp quá nhiều trở ngại.
Nếu ở quán bựa mà Cô Chai còn đéo hiểu/ đéo chịu hiểu được ý tưởng nền tảng của AI thì nowhere on giun cô có thể hiểu được nó. Trừ khi cô đọc blog tiếng bương. - Sat May 16, 08:48:00 AM 2020
- Thiên cơ said... (4697)
- Một ví dụ điển hình của việc giữa ý tứ của giùn là anh đã đọc qua forum chân chính của con Lói. Cái đcm con này nổi tiếng mồm chó vó ngựa trên quán, mà trên forum của cỏn con phải dùng dùng cách hành văn khác đi, ý tứ hơn. Nhìn chung anh vẫn thấy cỏn hành văn ok trên forum, nhưng đcm đéo thể nào bằng được cách cỏn hành văn trên quán bựa. Lói ạ, anh vẫn ưng cách cô hành văn trên quán hơn
- Sat May 16, 08:54:00 AM 2020
- vnusaengland nguyen said... (4698)
- Ref: Mr.Trying (4691)
Nom cồng cô sao giống:
-Dẫu biết trời xanh là mãi mãi
-Mà sao nghe nhói ở trong tim
Của con nào nhớ về cụ, bạn khôngthân của Zì ấy nhở.
Cô quên rằng Zì là trùm Zâmcông, Minhcông, Chửicông à. Zì còn làm Hiệutrưởng lâu.
Khi nào mệt nhớ đá tí combo zânca + Chopin nhé Zì - Sat May 16, 09:02:00 AM 2020
- Day-dreaming said... (4699)

- nghỉ giải lao, tí dân ca nhẻ
trong lòng tôi gió xuân nào đắm đuối, cỏ nào trong mắt em xanh
trăng luyến ái lóng lánh mặt hồ
lửa hai người sưởi ấm cả đêm lạnh
Bao nhiêu năm sau như mây bay, bước chân đổi thay làm hai ta khó nắm được tay
Đời kiếp này có bao nhiêu người
như em và tôi bị nhấn chìm bởi những đêm trăng nước
Chợt những ngày xưa hiện lại
quyến luyến quên về...trên hồ Baikal
Bao nhiêu năm sau chuyện cũ bay theo mây, nhưng những dịu êm như tuyết băng không tan
Đời kiếp này quá ngắn ngủi, không nói đủ thâm tình như băng tuyết không tan
Đợi một ngày em chợt hiện ra, như Baikal hồ trong veo thần bí - Sat May 16, 12:00:00 PM 2020
- Day-dreaming said... (4700)
- Đây là tiêu biểu kiểu dịch tên địa danh quốc tế ra tiếng nước mẹ
Baikal thành bei jia er, Bối Gia Nhĩ, chẳng nghĩa mẹ gì
trong văn viết lại không có kiểu viết hoa như kiểu Giùn...ko đoán được trừ phải đi gúc - Sat May 16, 12:08:00 PM 2020
- Là Sao said... (4701)

- Thank you Zi and Co Thien Co for the wonderful discussion about AI and ML.
- Sat May 16, 03:06:00 PM 2020
- Asinerum Project Commander said... (4702)
- Khi Bò dã thành mẹ taychuyên AI, thì Zì sẽ zạy Bò cách hách AI.
Dạikhái, Bò dưa ảnh Ông Cụ vào cho AI chạy, thì AI khăngkhăng dó là Dống Cứt hehe.
Việc này không khó, chỉ cần Bò nắm dược kiếntrúc AI Model của ông máy.
Những món bảomật thôngzụng hiệntại như vântay, tròngmắt, khuônmặt, giọngnói, etc, dều thế cả, hách cực dơngiản, chả khó déo gì.
Vấndề là, muốn hách vântay, chảzụ, thì chúng cô cần có vântay gốc (dặng nghiêncứu phai mãhóa nó). Mà khi dã có phai gốc, thì làm mẹ quả vântay clone cho nhanh, chứ cần déo gì hách.
Nhưng Zì muốn nói là, zù chúng cô login vào máy bằng vântay, thì các anh háchcơ cothe chỉ cần nhét một nhánh cỏ, mà máy cũng zuyệt.
Nghĩa là, zù dược học zất kỹ, nhưng máymóc còn ngu lắm, chưa dạt mứcdộ như não người. - Sat May 16, 05:02:00 PM 2020
- Asinerum Project Commander said... (4703)
- Mời Bò nghe toànbộ quytrình zạy máy học cách nhậnzạng số biên tay MNIST mà con Cơ dã giảng. Rất trựcquan và chitiết:
https://cs.stanford.edu/people/karpathy/convnetjs/demo/mnist.html - Sat May 16, 05:10:00 PM 2020
- Asinerum Project Commander said... (4704)
- Và dây là demo trình nhậnzạng số biêntay, chỉ zùng thưviện Tensorflow chứ không zùng Keras (là thưviện con chạy trên nền Tensorflow).
Bò vẽ số từ 0 dến 9 vào ô hình vuông, gòy bấm "recognize", máy sẽ doán ra số Bò biên. Demo chạy hoàntoàn trên browser:
http://myselph.de/neuralNet.html - Sat May 16, 05:15:00 PM 2020
- Asinerum Project Commander said... (4705)
- Nhẽ Bò cũng tỏ, Zì kínhyêu cũng có vài thưviện AI riêng, zựng riêng, không cần external dependencies, và trọngyếu zùng trong lãnhvực tàichính tínzụng và thươngmại.
Zì sẽ release khi nao phùhợp. Bò chỉ cần nhớ rằng, các mạng thầnkinh của Zì chỉ có kíchthước tròmtrèm 3KB (ngang 1 cồng giảng trungbình của Zì tại Quán), và chạy hoàntoàn trên Browser. - Sat May 16, 05:39:00 PM 2020
- Asinerum Project Commander said... (4706)
- Zì nghiêncứu mạng thầnkinh từ quãng 1990s, nhưng phải mất trên chục mùa mý master dược nó. Dơngiản vì nó còn mớimẻ ngay cả mý quân Bương.
Bọn Bương cũng khốnnạn lắm. Chúng biên sách thế déo nào mà ngaycả các nãobộ thiêntài như Zì nom xong cũng déo hiểu cặc gì. Giờ thithoảng giở sách nghe lại thì cười vỡ mẹ zái, vì hehe bắt-quảtang con tácgiả cũng déo nắm cặc gì chữngchạc, chỉ giỏi hónghớt và chém-gió.
Những món Zì giảng Bò mấy bữa nay, gói gọn trong quãng 30 cồng something, nhưng là kếttinh của cả chục mùa nghiêncứu dó, dddd.
Chúng cô khongthe kiếm dược tại any dâu trên trầngian bài giảng nào zìa AI dơngiản, chínhxác, khúctriết, trựcquan, và thiếtthực, tươngdương.
Chúng Bương cũng toàn bọn tayngang thừa giấy vẽ voi. Chúng biên zài như thoòng, nhưng nom xong thì daphần quầnchúng thè mẹ Lồn ra, vì déo hiểu cặc gì. - Sat May 16, 05:51:00 PM 2020
- Asinerum Project Commander said... (4707)
- Mời Bò thử lên Coursera mà nom anh Andrew Ng trùm AI hoakỳ mẽo giảng bài hehe.
Dcm chỉ phí xèng thoy, Bò ạ. - Sat May 16, 05:55:00 PM 2020
- choi xong dong said... (4708)
- Hi chi bộ Bựa, cuối tuần rồi chuyển qua kênh văn nghệ tí nhỉ.
Bob Marley - Redemption Song
- Sat May 16, 09:38:00 PM 2020
- Asinerum Project Commander said... (4709)
- Bò Niubi tập dánh AI nên nhớ rằng, những framework họcsâu DL nhớn, tạng Tensorflow, sẽ chỉ hoạtdộng ngoan khi Bò dã luyện máy kỹcàng và save model [dã luyện ngoan] lại.
Chứ nếu chưa luyện máy {train} từ trước, thì dcm các ông nhớn ý chạy lâu dến muốn khùng mẹ luôn, mà kếtquả cũng déo như-ý, nhất là khi hoạtdộng onfly.
Chính vì vậy nên AI taylor-made của Zì daphần déo zùng các sángtác free dã có sẵn của Bương như Tensorflow, Theano, Pytorch, etc.
Zì sẽ cho Bò thử rite now. - Sat May 16, 10:30:00 PM 2020
- Asinerum Project Commander said... (4710)
- Ref: Asinerum Project Commander (4709)
Bò sẽ làm lại bàitoán 1+1 mà Zì dã giảng phía trên.
1. Dặng chạy bàitoán này mý Tensorflow, thì Bò cần có Google Chrome trong máy.
Các browser khác (như Firefox, Edge) cũng chạy tốt, nhưng Bò nên thử bằng chính sángtác của thằng Gúc, mý thiếtkế dedicated cho Tensorflow, sẽ tránh dược những thôngbáo lỗi dỏ như lòm. - Sat May 16, 10:36:00 PM 2020
- Asinerum Project Commander said... (4711)
- Ref: Asinerum Project Commander (4710)
2. Bò sẽ zùng Notepad (hay any text-editor nào) soạn phai TEST.HTML có nộizung sau:
<html>
<head>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.3.1/dist/tf.min.js"></script>
</head>
<body>
</body>
</html>
Phai này có nhiệmvụ nạp thưviện Tensorflow zìa máy. - Sat May 16, 10:42:00 PM 2020
- Asinerum Project Commander said... (4712)
- Ref: Asinerum Project Commander (4711)
3. Mở phai TEST.HTML dó bằng Google Chrome.
Bò sẽ nom một mànhình trắng như phau, không có gì cả. Kệ con mẹ nó. - Sat May 16, 10:44:00 PM 2020
- Asinerum Project Commander said... (4713)
- Ref: Asinerum Project Commander (4712)
4. Bấm nút F12, thì Bò sẽ nom một mànhình nhỏ bằng 1/2 mànhình hiệntại nhảy ra phía bên phải.
Nó sẽ có zấu nhắc ">" màu xanh nhonhỏ.
Dó chính là Console của Chrome, nơi Bò sẽ thaotác trựctiếp mý Tensorflow dã dược nạp trong phai TEST.HTML.
Và từ dây zìa sau, khi Zì bảo Bò "cốpbết vào Console", thì Bò biết phải làm gì gòy dó.
Dây là cách bìnhzân của các taychuyên biếngnhác, nhằm test các trình Web App chạy trên browser. - Sat May 16, 10:51:00 PM 2020
- Asinerum Project Commander said... (4714)
- Ref: Asinerum Project Commander (4713)
5. Cốpbết những zòng sau vào Chrome Console và gõ Enter:
const model = tf.sequential();
model.add(tf.layers.dense({units: 1, inputShape: [2]}));
model.add(tf.layers.dense({units: 64, inputShape: [1]}));
model.add(tf.layers.dense({units: 1, inputShape: [64]}));
model.compile({loss: 'meanSquaredError', optimizer: 'sgd'});
Console sẽ thôngbáo "undefined", vậy là Ngoan. - Sat May 16, 10:55:00 PM 2020
- Asinerum Project Commander said... (4715)
- Ref: Asinerum Project Commander (4714)
6. Nộizung của các lệnh này thì con Cơ dã giảng mẹ gòy.
Dó là, tạo một mạng thầnkinh có 3 tầng. Dcm tầng thứ nhất là tầng input, sẽ nhận 2 thôngsố dầuvào, tầng thứ hai là tầng-den aka hidden-layer, có 64 hạt thầnkinh, và tầng thứ ba là tầng output, sẽ xuất ra 1 kếtquả.
Hàm-mấtmát của mạng thầnkinh mini này là hàm "bìnhphương nhỏnhất" aka "meanSquaredError", còn phươngthức tínhtoán cựctrị là "sgd".
Bò vê chuột lên phía trên mà nom giảng của con Cơ zìa mấy món dó. - Sat May 16, 11:02:00 PM 2020
- Asinerum Project Commander said... (4716)
- Ref: Asinerum Project Commander (4715)
7. Cốpbết tiếptục những zòng sau vào Chrome Console và gõ Enter:
let xs = tf.tensor2d([[0, 1], [1, 2], [2, 3], [3, 4], [4, 5]], [5, 2]);
let ys = tf.tensor2d([1, 3, 5, 7, 9], [5, 1]);
Dây là sốmá huấnluyện cho máy họchành. Gồm 5 phép tính cộng những số nguyên dơngiản. Zòng trên là các sốhạng {x1 và x2}, zòng zưới là tổng {y}.
Gõ xong, thì Console cũng thôngbáo nhõn chữ "undefined". Vậy là ngoan. - Sat May 16, 11:07:00 PM 2020
- Asinerum Project Commander said... (4717)
- Ref: Asinerum Project Commander (4716)
8. Giờ dến phần luyện máy aka train. Cốpbết zòng sau vào Chrome Console gòy gõ Enter:
model.fit(xs, ys, {epochs:5000});
Lệnh này dơngiản là bắt máy học 5 ngàn lần mý các sốmá {xs} và {ys} dã có.
Dcm nhõn 5 ngàn lần, mà ông máy học lâu phát khùng luôn, cothe tới 5-10 phút. Dúng là vác zao-phay ra chém ruồi. - Sat May 16, 11:15:00 PM 2020
- Asinerum Project Commander said... (4718)
- Ref: Asinerum Project Commander (4717)
9. Khi nao Console thôngbáo
[[PromiseStatus]]: "resolved"
[[PromiseValue]]: ....
Nghĩa là máy dã luyện xong.
Nếu máy chưa luyện xong, thì sẽ chỉ nom dược zòng này:
[[PromiseStatus]]: "pending"
[[PromiseValue]]: .... - Sat May 16, 11:18:00 PM 2020
- Asinerum Project Commander said... (4719)
- Ref: Asinerum Project Commander (4718)
10. Bò chờ lâu dã phát Khùng chưa?
Hehe giờ thì cothe thử kếtquả của cú Học Máy bằng cách gõ những lệnh thử coi máy có học ngoan không, tạng như này.
model.predict(tf.tensor2d([1, 1], [1, 2])).print();
Dây là lệnh bắt máytính doán nom 1+1 bằng nhiêu. Dcm sainhầm vãi Lồn ra: quãng 1.9 something. - Sat May 16, 11:26:00 PM 2020
- Asinerum Project Commander said... (4720)
- Ref: Asinerum Project Commander (4719)
11. Dcm tómlại, mý taychuyên AI, thì việc chọn súng nào di bắn ông gì, cũng là một vấndề phứctạp.
Déo phải lúc déo nào vác dạibác ra chiếntrường cũng tốt. Sometimes zùng súng-trường lại ngoan hơn nhiều. - Sat May 16, 11:29:00 PM 2020
- Tỷ Phú Say Lìng said... (4721)

- Hehe sau 5 phút máy đùi vẫn đang pending

- Sat May 16, 11:29:00 PM 2020
- Asinerum Project Commander said... (4722)
- Hoy cho Bò nghỉ chút, mần tí zânca nào
- Sat May 16, 11:32:00 PM 2020
- Tỷ Phú Say Lìng said... (4723)
- Ra quãng 1.71. Lệch còn hơn của Zì. Túm lại copy paste cũng biết sơ cách đánh lười biếng tuy chưa hiểu mấy hehe.

- Sat May 16, 11:41:00 PM 2020
- Asinerum Project Commander said... (4724)
- Ref: Tỷ Phú Say Lìng (4723)
Biết nom nhời Zì, là ngoan gòy. Còn hiểu thì cứ từtừ.
Chỉ cần biết là, daphần các bàitoán AI trong thựctế của Bò chỉ cần nhõn chừng dó lệnh thoy. Nghĩa là số chữ cần biên déo kín một bàntay. - Sat May 16, 11:48:00 PM 2020
- Tỷ Phú Say Lìng said... (4725)
- Cái lệnh này:
model.predict(tf.tensor2d([1, 1], [1, 2])).print();
Nó có thể chạy luôn mà không cần phải bắt máy học? Mỗi tội kết quả hên xui? Như hình dưới đây bỏ đi lệnh bắt máy học 5000 lần.
- Sat May 16, 11:54:00 PM 2020
- Asinerum Project Commander said... (4726)
- Ref: Tỷ Phú Say Lìng (4725)
Không phải là máy không học, mà nó dã học dược một chút gòy dó. Aka trong lúc "pending", thì model dược cậpnhật liêntục.
Còn nếu hoàntoàn vôhọc, thì nó cho kếtquả ngẫunhiên.
Dúng là hênsui, déo biết dâu mà lần. - Sat May 16, 11:59:00 PM 2020
- Tỷ Phú Say Lìng said... (4727)
- Cô nào muốn học Đạisố tuyếntính làm nền có thể tham khảo playlist nài:
https://www.youtube.com/watch?v=fNk_zzaMoSs&list=PLZHQObOWTQDPD3MizzM2xVFitgF8hE_ab
- Sun May 17, 12:07:00 AM 2020
- Tỷ Phú Say Lìng said... (4728)
- Ref: Asinerum Project Commander (4726)
Đúng rồi Zì. E có hiểu lúc resolved là máy nó học xong 5000 lần với 5 cặp mẫu kia.
Còn nếu vô học aka bỏ lệnh model.fit() thì em thử vài lần rồi, kết quả hên xui. Lúc < 0, lúc >1 - Sun May 17, 12:20:00 AM 2020
- Asinerum Project Commander said... (4729)
- người dâu vừa dẹp vừa tài,
vừa sâu con mắt, vừa zài lỗ trôn
- Sun May 17, 12:41:00 AM 2020
- Tiểu Mỡ said... (4730)

- Ref: choi xong dong (4708)
Em về rồi nè, anh Choi, haha ,
Về xem Vý, thấy anh Choi đút cho 10.69204 XUT , Vui đéo tả nổi,
Lắc nào Choiii oiiii
mec xi cu cu - Sun May 17, 06:56:00 AM 2020
- Tiểu Mỡ said... (4731)
- Ref: vnusaengland nguyen (4652)
à, Còn anh V-nú nữa, 3 lần Vote lận .
Lúc nào anh buồn, cần thơ để thở thì nhớ Tới Mỡ nhơ. hahaha
vờn nhau tí nào
- Sun May 17, 07:20:00 AM 2020
- Day-dreaming said... (4732)
- Zì ơi em đếc hiểu gì, nhwung vẫn cốp bết vô cùng cẩn thận, biết có người rất cần mà giờ con cỏn vẫn ko để tâm...để chờ có ngày
- Sun May 17, 10:29:00 AM 2020
- Day-dreaming said... (4733)
- Ref: Tiểu Mỡ (4731)
Thế Mỡ biết vần cái món này đến độ nào rồi....Vần hay thế này mà miệ, giờ rủ bọn mem đi vần mà toàn thấy thíc nhậu nhẹt hơn thôi à. - Sun May 17, 10:32:00 AM 2020
- An Phong said... (4734)

- Ref: Asinerum Project Commander (4707)
Xưa tôi cũng hới mưng có theo khóa học của anh Andrew Ng được nửa chừng thì ù mẹ tai không theo nổi nữa. Nghĩ lại vẫn thấy xấu hổ nên chả bao giờ dám mở miệng gì về AI.
Thôi cúi đầu lạy Zì và Cô Thiên Cơ một lạy. Để tôi bắt đầu mò mẫm lại. - Mon May 18, 09:36:00 AM 2020
- Là Sao said... (4735)
- Zì giảng thánh quá.
Học về AI thì không vội được.
AI 20-niên nữa sẽ rất khủng khiếp. Chúng mình không đứng ngoài và thờ ơ được đâu. - Mon May 18, 11:32:00 AM 2020
- Asinerum Project Commander said... (4736)
- Học mà không hành, thì Bò chúng cô quá lắm cũng chỉ nên ông chó cắn cứt, ông vịt nhặt giun, mà thoy.
Vậy mời Bò thử zùng any côngcụ AI/ML/DL mần cho Zì quả trình máy "tính bìnhphương số thậpphân". Bằng ngônngữ déo nào cũng dược. Nhưng ngoan nhất thì zùng cáy déo gì mà các Bò khác cothe test trên mạng hoặc chính tại máydùi mình.
Giải nhất 30+ xuteng cho con nào code ngoan nhất và cho kếtquả dẹp nhất và trong thờigian sớm nhất.
Giải vè Bựa 04/2020 dã kếtthúc. Chả cần tính cũng biết em Mỡ cắn giải nhất hehe. Mời em Mỡ dưa nút Xuteng cho Zì trao giải 30.66 xuteng. Ngoài ra Zì tự quyếtdịnh trao các giải khuyếnkhích 6.66 xuteng cho các con Batê, Dong Xèng, Ngựa, và em Dầy Mình. Chúcmừng các vè-hào Quán Bựa. - Mon May 18, 05:18:00 PM 2020
- Antonio Tran said... (4737)

- Ref: Asinerum Project Commander (4668)
Thành Zì và cø Thiєn Cə vє̀ nhw̃ng loät cø̀ng chʌ́t lïm vє̀ AI/ML.
Đã có anh bò nào thw̑ və́i cú training bя̀ng 2 triє̈u chwa nhє̑ ?
Anh có thя́c mя́c là və́i cú training là 2 triє̈u result = 1,885 , còn training là 200 ngàn thì result läi sexy hən = result = 1,896.
Link test : https://repl.it/@TonyTran2/BuaML
- Mon May 18, 06:40:00 PM 2020
- Asinerum Project Commander said... (4738)
- Ref: Antonio Tran (4737)
Hehe anh Bò thử luyện Máy mý số epoch bằng 100,000 thì kếtquả 1+1 còn ngoan hơn nữa ý chứ (bằng 2.0001 something).
Cơmà cho nó cộng các số khác, chảzụ 1+8, thì lại không ngoan nữa (bằng 7.5 something). - Mon May 18, 07:33:00 PM 2020
- Ngựa - PhoBitcoin.com said... (4739)
- Zì kính yêu còn baonhiêu ấpủ làm sao cóthể mỏi gối chùnchân.
- Mon May 18, 08:34:00 PM 2020
- Ngựa - PhoBitcoin.com said... (4740)
- Cáy dcm Bê bỏn tính giáđiện kiểu éo gì tôi 3-4 chỗ chỗ nào cũng tăng gần gấp đôi. Kiểu này chắc nghiên cứu vụ lắp tấm nănglượng mặttrời mà xài chứ sống thế đéo nào được với Bê nhỉ
- Mon May 18, 08:35:00 PM 2020
- Tiểu Mỡ said... (4741)
- Ref: Day-dreaming (4733)
Mỡ không học môn này mà chủ yếu tập Gym thoy,
Môn này Mỡ thờ ơ lắm, vì rằng đi tập Gym cầm ta sướng hơn ôm eo chăng, hyhy
-------
Bạn Minh đu môn này à? rèn môn này, thi thoảng tiệc tùng lên bung vài bước cho dân trầm trồ.
Có bận lò mổ cũ tổ chức party, có 1 VS hứng thú với các dancer , đã lên nhảy làm cả bọn trầm trồ - há mồm vì khả năng nhảy dẻo - uốn lượn cơ của của ẻm,
Mộ quá, !!!
- Tue May 19, 12:00:00 AM 2020
- Tiểu Mỡ said... (4742)
- Ref: Asinerum Project Commander (4736)
Dỳ trao giải rồi à??
Em tưởng em cắn giải phụ thôi chứ,
Vú À vý em đây, cảm tạ Zỳ,
-- Chân thành cảm ơn các Bựa đã chấm bài cho Mỡ,
Sự hào sảng của các Bựa làm MỠ rung động tận đáy con tym
Thưa Dỳ, em xòe vý
- Tue May 19, 12:06:00 AM 2020
- Day-dreaming said... (4743)
- Ref: Asinerum Project Commander (4736)
Dạ ví em đây, vinh dự quá
- Tue May 19, 11:29:00 AM 2020
- Đong Xèng said... (4744)
- Được Zì trao giải sướng rung cả lông bẹn, hehe. Tạ Zì Tạ Zì
- Tue May 19, 07:25:00 PM 2020
- K&L Services said... (4747)
- Thành Zì và anh Thiên Cơ về bài giảng ML/AI thật hay. Tôi trình còi nên đọc vào chỉ hiểu được ý tưởng tổng quan thôi.
Tôi cũng đang lọ mọ học món này, nên bốt thử bài giải bằng Python tính bình phương số thập phân như sau:
import numpy as np
import keras
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import Adam
from keras import regularizers
model = Sequential()
model.add(Dense(8, activation='relu', kernel_regularizer=regularizers.l2(0.001), input_shape = (1,)))
model.add(Dense(8, activation='relu', kernel_regularizer=regularizers.l2(0.001)))
model.add(Dense(1))
model.compile(optimizer=Adam(),loss='mse')
# generate 10,000 random numbers in [-50, 50], along with their squares
x = np.random.random((10000,1))*100-50
y = x**2
# fit the model, keeping 2,000 samples as validation set
hist = model.fit(x,y,validation_split=0.2,
epochs= 15000,
batch_size=256)
# check some predictions:
print(model.predict([4, -4, 11, 20, 8, -5]))
# result:
[[ 16.633354]
[ 15.031291]
[121.26833 ]
[397.78638 ]
[ 65.70035 ]
[ 27.040245]] - Wed May 20, 11:02:00 AM 2020
- pe^te^211 said... (4748)
- Cảm ơn Zì bím hồng đã khen và thưởng.
Zì chờ anh chút để tạo ví đựng. - Wed May 20, 06:06:00 PM 2020
- Lìu Tìu said... (4749)
- Hômnay, 21 tháng 5, sinhnhật quán.
Chúc Zì sứckhỏe.
Chúc bọn bù-bựa họchành ngày càng tấntới. - Thu May 21, 09:31:00 PM 2020
- Mr.Trying said... (4750)
- Hôm nay sinh nhật quán Bựa ah, Chúc Gì và các Bựa luôn bình an, hạnh phúc và may mắn!
- Thu May 21, 09:36:00 PM 2020
- Mr.Trying said... (4751)
- Ngày này cách đây một cơ số năm, tôi đã đánh mất một người con gái đến giờ tôi vẫn hoài niệm thương nhớ và bồi hồi xót xa.
Ngày đó, tôi dân quê lên tỉnh học, dân nông thôn miền trung nắng gió luôn mang trong mình sự tự ti mặc cảm và tự ái vặt vảnh và sỉ diện vớ vẫn. hehe. nhiều khi nghỉ lại thấy xấu hổ quá.
Tôi vốn dĩ, không ưa đi học chỉ mong đi lên thành phố đong xèng như những nam thanh nữ tú cùng quê. Đến Tết đứng ở ngã ba đường làng khệnh khạng kể chuyện trên trời dưới bể. nên lên phố cái là tôi chăm chăm lao đi làm thêm Nhưng may sao tôi cứ mỗi lần đến kỳ thì là được ngồi với thằng bạn bốn mắt, răng vẫu nên điểm số tôi cũng khá cao.
Nên kỳ kiến tập năm đó, tôi cũng được xếp chung nhóm, mà tụi lớp tôi hồi đó cứ quen gọi là nhóm nhà trắng. Vì nhóm tôi toàn còn nhà giàu học giỏi, xinh đẹp và thơm tho. Chỉ lọt trong đó có tôi và thằng bạn bốn mắt nhưng thông minh đéo tả, nó mà làm tính nhẩm thì nhanh hơn bẻ que. Cái gì nó cũng đéo biết chỉ đến lúc cộng tiền ăn, chia nhau là tôi mới phục tài nó. hehe
Tôi cứ thế lặng lẽ lặng lẽ, cũng chả hòa nhập gì. Thời đó thực tập về quê nên ở nhà một nhà dân. Lớp tập trung tham quan cảnh xung quanh, tối cứ nằm lầm lỳ ở nhà. Cảnh quê thì với tôi nó thường lắm, có mẹ gì mà phải đi xem giữa trời đang nắng.
Được cái, tôi quen chân lắm tay bùn nên nhà cô chú có việc gì tôi cũng xung phong phụ giúp, sửa bóng đèn, vặn lại cái xe tôi cũng lăn săn lăn săn.
Rồi một đêm thu không có cái lá vàng nào rơi, trời tối như bao đêm chẳng có mẹ gì hay thì bổng nghe tiếng ầm ĩ. Tôi cũng kệ, nằm đọc mấy quyển sách cũ mua ở vệ đường. Tôi nghe tiếng bọn con gái vừa chạy vè vùa khóc oe oe, tôi mới bước ra chủ yếu tôi định xem thế nào thôi, chứ ngữ như tôi làm sao có cửa an ủi. hu hu tủi thân quá.
Tôi đang ngó nghiêng thì một đám trai làng cầm gậy chạy vào nhà tìm mấy thằng choai lớp tôi. Cả nhóm cả bọn con trai trốn biệt, mỗi tôi ở nhà, thằng răng vẫu hôm nay cũng dỡ chứng lên xóm nhà lá chơi với thằng bạn cùng quê chưa về. Bon trai làng nhìn tôi một lượt định tóm lấy tôi thì cô chú chủ nhà bảo tôi tối giờ vẫn ở nhà, và mấy bọn con gái khóc oe oe dữ quá nên bọn nó bỏ đi. Sau đó, bọn con gái mới kể mấy đứa con trai trên xóm nhà lá bị đánh chảy máu cần đưa hòm sơ cứu lên. Tôi cứ sợ thằng bạn răng vẫu thần hộ mệnh mỗi kỳ thi của tôi có mệnh hệ gì thi tôi biết bấu vướu vào đâu nên tôi xung phong đi. Mà thực ra, tôi nói xung phong là nói cho oai đấy thôi, chứ còn mỗi tôi nam nhi đại trượng phu đương nhiên là phải đương đầu với thử thách chông gai rồi phỏng các bựa ? Tôi đang lúi húi chuẩn bị cái chổi cùn đốt lên soi tỏ con đường cách mệnh tôi sắp bước, thì bổng em nhẹ nhàng đế bên tôi thì thầm bảo M đi cùng H nhé. Trong tình huống của tôi, đi một đoạn đường dài gần cả cây số, đường quê xa thăm thẳm có người đi cùng thì sướng biết bao nhiêu, huống gì lại có người đẹp nhất lớp đi cùng. Tính tôi vốn cả nể, đặc biệt là đối với con gái đẹp nên đương nhiên là tôi đồng ý. Thế là hai tôi lặng lẽ bước đều bước dưới ánh sáng của cây chổi cùn, mà lòng như bừng nắng hạ.
- Thu May 21, 10:29:00 PM 2020
- Day-dreaming said... (4752)
- Ref: Mr.Trying (4751)
Ủa bốt nốt đi chớ.. hay cảm xúc quá tay phím nọ bấm phím kia... - Fri May 22, 01:10:00 PM 2020
- vnusaengland nguyen said... (4753)
- Ref: Mr.Trying (4751)
Ơ, sao đang post lại bắt chước thím nào rặnỉa mý khuấybột thế. - Fri May 22, 01:14:00 PM 2020
- Giùn gộc said... (4754)
- Rồi lại kèn sáo, mút cu vang-lừng, chi-bộ mong chờ đéo gì chuyện ngun-tình 3xu ngập-ngụa cõi mạng?
Mời a Thông Ba-nhan ngoi lên, biên chuyện địt phò Đông-Hoản, đá phạch gái Quất-Lâm quê nhà, nom hấp-dẫn hơn. - Fri May 22, 03:00:00 PM 2020
IPFS: INTERPLANETARY FILE SYSTEM - P24
Subscribe to:
Posts (Atom)
4. Zĩ sẽ bỏqua phần các anh Bương tínhtoán {thetaZero} mý {thetaOne} theo phongcách kinhviện từ mùa 18xx, mà nhảy mẹ luôn vào môn Zạy Máy Leo Núi.